
وب سایت معروف Rbloggers اقدام به معرفی 5 کتاب برتر در آموزش زبان برنامه نویسی R کرده است. فایل این کتابها با کلیک روی نام آنها قابل دانلود خواهد بود.
وب سایت معروف Rbloggers اقدام به معرفی 5 کتاب برتر در آموزش زبان برنامه نویسی R کرده است. فایل این کتابها با کلیک روی نام آنها قابل دانلود خواهد بود.

Data Mining یک فرایند کلی است برای مرتب سازی مجموعه ای از داده های بسیار، این تکنیک عموما توسط سازمانهای تجاری و تحلیلگران مالی مورد استفاده قرار می گیرد ولی این قانون بطور فزاینده ای توسط دانشمندان برای استخراج اطلاعات از میان مجموعه های داده ی بسیار بزرگ که توسط آزمایش های مدرن و شیوه های مبتنی بر مشاهده گرد آوری شده مورد بهره برداری قرار می گیرد.از این نوع استخراج داده برای تولید گزارشات مدیریتی و گزارشاتی که برمبنای آنها تجارتی انجام می شود، استفاده می شود.
در این که کتاب توسط آقای مهدی صمدی به فارسی ترجمه شده است. به بررسی داده کاوی با استفاده از زبان برنامه نویسی R پرداخته است که نسخه اصلی کتاب نیز به همراه نسخه فارسی آن برای دانلود قرار گرفته است.
تعداد صفحات کتاب : ۲۷۶ صفحه
اندازه فایل : ۷٫۹۲MB


گوگل و مایکروسافت بهتازگی یادگیری مبتنی بر شبکههای عصبی را به برنامههای ترجمه خود اضافه کردهاند. گوگل گفته است از یادگیری ماشینی بهمنظور تهیه فهرستی از آهنگهای پیشنهادی استفاده میکند. Todoist میگوید از هوش مصنوعی بهمنظور مشخص کردن زمان پایان یافتن کارها استفاده میکند. Any.do ادعا کرده است بات مبتنی بر هوش مصنوعی این سایت قادر است یک سری از وظایف کاربران را خود انجام دهد. جالب آنکه تمام این شرکتها تنها در یک هفته این صحبتها را مطرح کردهاند. در حالی که به نظر میرسد تعدادی از این گفتهها بیشتر تکنیکهای تبلیغاتی هستند و شرکتها سعی کردهاند، اینگونه وانمود کنند که برنامههای آنها مورد علاقه طیف گستردهای از کاربران قرار دارد. اما در بعضی موارد این فناوریها تأثیرگذاری محسوس خود را نشان دادهاند. هوش مصنوعی، یادگیری ماشینی و شبکههای عصبی همگی به توصیف راهکارهایی میپردازند که به کامپیوترها اجازه میدهند فعالیتهای خود را به شکل پیشرفتهتر و بر مبنای شرایط محیطی انجام دهد. در این بین تعدادی از توسعهدهندگان برنامههای کاربردی برای توصیف برنامه هوشمند خود به یک شکل از این اصطلاحات استفاده میکنند، اما واقعیت این است که این فناوریها به طور کامل با یکدیگر متفاوت بوده و هر یک کارکرد خاص خود را دارند. ما در این مقاله سعی خواهیم کرد به بیانی ساده هر یک از این فناوریها را مورد بررسی قرار دهیم.
شبکههای عصبی با تقلید از مغز انسان دادههای پیچیده را تحلیل میکنند
(ANN)
(سرنام Artificial Neural Networks) به گونهای از شبکههای عصبی مصنوعی
گفته میشود که رویکرد ویژهای از مدل یادگیری را مورد استفاده قرار
میدهند و از رویکرد سیناپسها در مغز انسان الگوبرداری میکنند.
رویکردهایی که در محاسبات سنتی از آنها استفاده میشود، به این شکل عمل
میکنند که یک سری عبارات منطقی را برای انجام وظیفهای مورد استفاده قرار
میدهند. اما در شبکههای عصبی مجموعهای از گرههای شبکه (شبیه به
سلولهای عصبی عمل میکنند) و یالها (Edges) که شبیه به سیناپسها عمل
میکنند برای پردازش دادهها مورد استفاده قرار میگیرند. ورودیها به درون
سامانه وارد شده، مورد پردازش قرار گرفته و یک سری خروجی را تولید
میکنند. در ادامه، خروجیهای تولید شده با دادههای شناخته شده مورد
مقایسه قرار میگیرد.

به
طور مثال، در نظر دارید به یک کامپیوتر آموزش دهید یک سگ را در یک تصویر
شناسایی کند. برای این کار میلیونها تصویر از سگهای مختلف را به درون این
شبکه وارد میکنید و سپس تصاویری که سامانه تشخیص داده است شبیه به سگها
هستند را دریافت میکنید. در این گام، عامل انسانی میتواند به شبکه عصبی
اعلام دارد کدامیک از خروجیها دقیقاً تصویر متعلق به یک سگ است. به این
ترتیب، مسیرهایی که منتهی به تشخیص درست میشوند را روی یک شبکه عصبی
مصنوعی تقویت میکنید. با تکرار این پروسه به دفعات، شبکه عصبی مصنوعی به
اندازهای مهارت پیدا میکند که قادر خواهد بود تصویر متعلق به سگها را با
دقیقترین جزییات شناسایی کند. برای آنکه از نزدیک با شیوه کارکرد این
شبکهها آشنا شوید، پیشنهاد میکنم سرویس Quick Draw گوگل را مورد آزمایش قرار دهید.
در
این پروژه مطالعاتی گوگل به شبکهای عصبی یاد میدهد تصاویری که مردم
ترسیم میکنند را شناسایی کند. به طور مثال، در شکلهای 1 و 2 شبکه عصبی
موفق شد، شکل ترسیمی را شناسایی کرده و به کاربر بگوید (به شکل صوتی) این
تصویر یک گربه است. حتی اگر مهارتهای شما در رسم تصاویر ضعیف باشد، این
شبکه عصبی باز هم قادر است تصاویر را تشخیص دهد. با وجود این، شبکههای
عصبی مصنوعی را نمیتوان برای حل تمام مشکلات مورد استفاده قرار داد. اما
زمانی که با دادههای پیچیدهای سروکار دارید، آنها بهترین گزینه هستند.
با توجه به اینکه فرآیند ترجمه متون کار تخصصی و سختی به شمار میرود،
گوگل و مایکروسافت از این رویکرد قدرتمند در ارتباط با برنامههای ترجمه
خود استفاده کرده و نتایج خوبی نیز به دست آوردهاند. همه ما تا به امروز
ترجمههای ضعیف بسیاری را مشاهده کردهایم، اما شبکههای یادگیری عمیق عصبی
به یک سامانه اجازه میدهند بهمرور زمان از ترجمههای صحیحی که انجام
داده است نکات بیشتری را یاد بگیرد.

شکل 1 - یک تصویر ابتدایی که توسط عامل انسانی رسم شده است.
مشابه چنین رویکردی در ارتباط با تشخیص گفتار نیز وجود دارد. زمانی که گوگل شبکههای عمیق عصبی را به سرویس صوتی خود Google Voice اضافه کرد، نرخ اشتباهات این برنامه به میزان 49 درصد کم شد. البته این قابلیت هیچگاه کامل نخواهد بود، اما بهمرور زمان ویژگیهای عصبی بیشتری به موازات این دستاورد به برنامهها افزوده خواهد شد. به هر ترتیب، با استفاده از رویکرد یادگیری مبتنی بر شبکههای عمیق عصبی، تحلیل دادههای پیچیدهتر روزبهروز پیشرفت خواهد کرد، به طوری که ویژگیهای طبیعیتری به برنامههای کاربردی اضافه خواهد شد.
یادگیری ماشینی با رویکرد تمرین بیشتر باعث پیشرفت کامپیوترها میشود
یادگیری
ماشینی یکی از پراستفادهترین اصطلاحاتی است که این روزها آن را مشاهده
میکنید. هرگونه تلاشی که درنهایت به یک کامپیوتر اجازه دهد به شکلی مستقل و
پیشرفته کارهای خود را انجام دهد، در زمره دستاوردهای این شاخه قرار
میگیرد. اگر در نظر داشته باشیم این اصطلاح را به شکل تخصصیتری توصیف
کنیم، باید بگوییم یادگیری ماشینی به سامانههایی اشاره دارد که در آن
عملکرد یک ماشین در انجام یک وظیفه منحصراً بر پایه تجربیاتی است که از
اجرای همان وظیفه به دست آورده و بهبود پیدا کرده است. شبکههای عصبی مثالی
از یادگیری ماشینی هستند. اما این فناوری را به اشکال مختلفی میتوان
پیادهسازی کرد. یکی دیگر از زیرشاخههای یادگیری ماشینی که این روزها
بهکرات شاهد آن هستیم، یادگیری تقویتی (Reinforcement Learning) است. در
یادگیری تقویتی، کامپیوتر وظیفهای را انجام داده و در ادامه نتایج مورد
بررسی قرار میگیرد. بازی شطرنج مثال خوبی در این زمینه است. یک کامپیوتر
یک بازی شطرنج را به طور کامل انجام میدهد و درنهایت یا برنده بازی میشود
یا در بازی شکست میخورد. اگر کامپیوتر برنده این بازی باشد، به مجموعه
حرکاتی که در طول بازی انجام داده و به پیروزی کامپیوتر منجر شدهاند، یک
امتیاز مثبت تخصیص داده میشود.
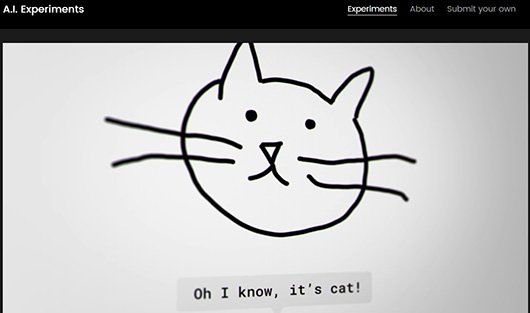
شکل 2 - شبکه عصبی تصویر را شناسایی میکند و اعلام میدارد که یک گربه است.
در
ادامه، بعد از آنکه میلیونها بار این بازی را انجام داد، سامانه بر
مبنای نتایجی که در این مدت به دست آورده است میتواند تشخیص دهد که چه
حرکاتی احتمال برد او را در بازیها بیشتر میکنند. در شرایطی که شبکههای
عصبی برای انجام کارهایی همچون تشخیص الگوها در تصاویر کارکرد خوبی دارند،
اما در مقابل مدلهای دیگر یادگیری ماشینی میتوانند بهمنظور انجام یک سری
وظایف خاص به صورت بهینهسازی شده مورد استفاده قرار گیرند. گوگل در این
ارتباط گفته است: «برنامه موسیقی به این شکل عمل میکند که قطعه مورد علاقه
شما را پیدا میکند و هر زمان شما اراده کنید که به موسیقی گوش فرا دهید
آن قطعه را برای شما پخش میکند.»
این برنامه بر مبنای الگوی رفتاری
شما کار کرده و فهرستی را منطبق با علایق شما آماده میکند. اگر شما از
قطعهای که برایتان انتخاب شده است راضی نباشید، به منزله آن است که سیستم
شکست خورده است. با این حال، اگر هریک از قطعات موسیقی انتخابی را قبول
کنید، سیستم این نتیجه مثبت را ثبت کرده و رویکردهایی که درنهایت بهمنظور
ساخت یک فهرست شخصی مورد استفاده قرار میگیرند را تقویت میکند. به طور
مثال، اگر برای اولین بار برنامه موسیقی گوگل را باز کنید، با پیشنهادات
درهم و برهمی روبهرو میشود. اما هرچه بیشتر از این برنامه استفاده کنید
پیشنهادات هدفمندتر و دقیقتری را مشاهده خواهید کرد. این رویکرد دقیقاً در
ارتباط با یوتیوب نیز صدق میکند. کافی است با حساب کاربری خود وارد
یوتیوب شوید و به جستوجو بپردازید. در زمانهای بعد مشاهده خواهید کرد
یوتیوب فهرستهایی را در اختیار شما قرار میدهد که در تشابه نزدیکی با
علایق شما قرار دارند. با وجود این باز هم یادگیری ماشینی را در همه امور
نمیتوان مورد استفاده قرار داد و ممکن است در بعضی موارد یک سری
ناهمگونیهایی را مشاهده کنید.
به طور مثال، اگر هر 6 ماه یک بار از
برنامه موسیقی گوگل استفاده کنید، پیشنهاداتی که ارائه میشوند هیچگاه باب
میل شما نخواهند بود. به عبارت دقیقتر، این رویکرد تنها زمانی دقیق و
درست عمل میکند که شما به دفعات از آن استفاده کنید.
به هر ترتیب،
یادگیری ماشینی به عنوان یکی از پرکاربردترین اصطلاحات روز دنیای فناوری
نکات مبهم بسیاری در مقایسه با شبکههای عصبی دارد. ولی نشان داده است، اگر
از نرمافزاری استفاده کنید و بازخوردهای مرتب و منظمی را در اختیار آن
برنامه قرار دهید، بهمرور زمان شاهد بهبود عملکرد آن برنامه خواهید بود.
هوش مصنوعی به هر شیء هوشمند اطلاق میشود
دقیقاً
مشابه با شبکههای عصبی که شکلی از یادگیری ماشینی هستند، یادگیری ماشینی
خود شکلی از هوش مصنوعی است. با وجود این، گروهبندیهای دیگری نیز در زیر
شاخه هوش مصنوعی قرار میگیرند، اما آنگونه که باید و شاید مورد توجه
نیستند، به طوری که در ارتباط با بعضی از این گروهها ارائه یک تعریف واحد
کمی بیمعنا به نظر میرسد. در حالی که در تعدادی از فیلمهای علمی و تخیلی
یک سری تصورات ذهنی را مشاهده میکنیم. اما واقعیت این است که در بعضی از
حوزههای هوش مصنوعی به اندازهای از پیشرفت دست پیدا کردهایم که تا همین
چند سال پیش تقریباً تصور آن را هم نمیکردیم. به طور مثال، نویسهخوانی
نوری (OCR) (سرنام Optical Character Recognition) از جمله نقاط عطف هوش
مصنوعی به شمار میرود. این فناوری در شرایطی این روزها به سهولت در اختیار
ما قرار دارد که تا چند سال پیش اگر در نظر داشتید این فناوری را در
اختیار داشته باشید، باید هزینه سنگینی پرداخت میکردید. امروزه
ابتداییترین گوشیها نیز قادر هستند یک سند را اسکن و آن را به متن تبدیل
کنند. این فناوری به اندازهای پیشرفت کرده است که بهراحتی میتوانید
گوشی خود را روی یک تصویری که به طور مثال لغات فرانسوی در آن قرار دارد
نگه داشته و برنامه به طور همزمان کلمات را شناسایی و آنها را به زبان
مورد نظر شما ترجمه میکند. این فناوری دیگر هیجانبرانگیز تلقی نمیشود و
بیشتر به عنوان یکی از وظایف ابتدایی هوش مصنوعی از آن نام برده میشود.
دلیل اینکه چنین کار سادهای در مجموعه هوش مصنوعی قرار میگیرد به این
دلیل است که ما دو رویکرد کلی ضعیف (Weak or narrow) و قوی (Strong) را در
حوزه هوش مصنوعی داریم. ضعیف در حوزه هوش مصنوعی اشاره به سامانههایی دارد
که برای انجام یک یا چند وظیفه خاص طراحی شدهاند. به طور مثال، سیری اپل و
Google Assistant دو برنامه کاملاً قدرتمند هستند، با وجود این در این
گروه قرار میگیرند به دلیل اینکه دامنه فعالیتهای آنها به یک سری
دستورات صوتی و پاسخ دادن به آنها محدود میشود. در حالی که تحقیقات
گستردهای برای پیادهسازی چنین قابلیتهایی از سوی گوگل و اپل انجام شده
است، اما باز هم به این چنین برنامههایی در حوزه هوش مصنوعی weak گفته
میشود.
واقعیت این است که در بعضی از حوزههای هوش مصنوعی به اندازهای از پیشرفت دست پیدا کردهایم که تا همین چند سال پیش تقریباً تصور آن را هم نمیکردیم.
قوی در مقابل ضعیف قرار دارد. واژه قوی اشاره به هوش مصنوعی عمومی (AGI) (سرنام Artificial General Intelligence) دارد. در بعضی منابع از واژه هوش مصنوعی کامل (full AI) نیز استفاده میشود. این سامانهها قادر هستند همانند انسانها هر وظیفهای را انجام دهند و همان گونه که در مقاله شماره قبل «همزیستی مستقل انسان و هوش مصنوعی» به آن اشاره کردیم، هنوز چنین سامانههایی ساخته نشدهاند. در نتیجه نباید در آینده نزدیک در انتظار روباتهای هوشمندی همچون Alan Tudky باشید که بتوانند تمام کارهای روزمره زندگی را انجام دهند. از آنجا که تقریباً تمام سامانههای هوشمندی که از آنها استفاده میکنید در رده weak AI قرار دارند، هر زمان عبارت هوش مصنوعی را در ارتباط با یک برنامه مشاهده کردید، بدانید که منظور این است که برنامه فوق فقط هوشمند است. این احتمال وجود دارد که جملات یا پیشنهادهای جالب توجهی را در این ارتباط مشاهده کنید، اما باید این واقعیت را بدانید که هنوز هیچیک از این برنامهها قادر نیستند با هوش انسانی رقابت کنند.
دقیقاً مشابه با شبکههای عصبی که شکلی از یادگیری ماشینی هستند، یادگیری ماشینی خود شکلی از هوش مصنوعی است
در شرایطی که معناشناسی این اصطلاحات کمی پیچیده است، اما در مقابل پژوهشهای علمی و دستاوردهایی که در حوزه هوش مصنوعی به دست آمده کارایی خود را بهخوبی نشان دادهاند. به طوری که امروزه در زندگی روزمره خود تأثیرات این پژوهشها را مشاهده میکنیم. به طور مثال، هر زمان گوشی هوشمند شما مکانی که خودروی خود را در آنجا پارک کردهاید را به شما یادآوری میکند، چهرههایی را درون تصاویر مختلف شناسایی میکند یا در هنگام جستوجوی معمول نتایج مشابهی را به شما نشان میدهد یا قادر است تصاویر مربوط به سفرهای مختلف را به شکل دقیقی برچسبگذاری و طبقهبندی کند در تمام این موارد به طور مستقیم و غیر مستقیم از هوش مصنوعی استفاده کردهاید. تا حدی میتوانیم تعریف هوش مصنوعی را به معنای هوشمندتر کردن برنامههای کاربردی بسط دهیم. رویکردی که همه ما به دنبال آن هستیم. این هوشمندی در شرایطی است که یادگیری ماشینی و به پیروی آن شبکههای عمیق عصبی به شکل منحصر به فردی به منظور انجام یک سری از وظایف آن هم به شکلی ایدهآل مناسب هستند.
اما به این نکته توجه داشته باشید زمانی که یک برنامه اعلام میدارد که از هوش مصنوعی استفاده میکند این حرف کمتر به معنای آن است که این برنامه از یادگیری ماشینی استفاده میکند. همین موضوع در ارتباط با شبکههای عصبی نیز صادق است. گفتن این حرف که یک برنامه از یادگیری ماشینی به منظور انجام بهتر کارها استفاده میکند، تقریباً شبیه به گفتن این جمله است که یک دوربین بهتر است، به این دلیل که دیجیتالی است؛ بله دوربینهای دیجیتالی برای انجام بعضی از کارها بهتر از دوربینهای نگاتیو قدیمی هستند، اما این حرف لزوماً به معنای آن نیست که هر عکس دیجیتالی بهتر از یک عکس آنالوگ خواهد بود. به عبارت دیگر، خوب بودن هرچیز به طرز استفاده از آن وسیله بستگی دارد. تعدادی از شرکتها این توانایی را دارند تا شبکههای عصبی قدرتمندی را توسعه دهند که بهخوبی قادر به انجام وظایف پیچیده هستند، به طوری که زندگی بهتری را برای ما به ارمغان میآورند.
اما تعداد دیگری از این شرکتها تنها یک برچسب یادگیری ماشینی روی محصولات خود قرار میدهند. در حالی که در عمل محصول آنها همان کاری که در گذشته انجام میداده است را بدون هیچگونه تغییری انجام میدهد. اما بدون شک در پشت صحنه، یادگیری ماشینی و شبکههای عصبی فناوریهای هیجانبرانگیزی هستند. با وجود این به این نکته توجه داشته باشید، هر زمان در توضیحات یک برنامه چنین اصطلاحاتی را مشاهده کردید، این حرف به معنای آن است که این برنامهها احتمالاً کمی هوشمندتر است. در نتیجه همانند گذشته، ابتدا یک برنامه را مورد استفاده قرار دهید و بررسی کنید که این برنامه تا چه اندازه برای شما مفید بوده است، آنگاه درباره آن قضاوت کنید.
==============================
شاید به این مقالات هم علاقمند باشید:
به گزارش ایسنا به نقل از دیجیتال ترندز، یک شرکت به نام (Gamalon)گامالون موفق به توسعه یک فناوری جدید برای یادگیری ماشینی به نام BPS شده که میتواند سرعت روند یادگیری ماشینی را بیش از 100 برابر افزایش داده و در حال حاضر در دو برنامه تجاری آلفا به نامهای "ساختار گامالون" (Gamalon Structure)و "همتای گامالون" (Gamalon Match) در دسترس است.
در رونمایی از این فناوری جدید، این شرکت نشان داد که چگونه BPS در مقایسه با فناوری یادگیری ماشینی"ذهن عمیق" (DeepMind)گوگل کار میکند.
در فناوری هوش مصنوعی گوگل، وقتی یک جسم واحد مانند لامپ توسط کاربر ترسیم میشود، هوش مصنوعی با مقایسه همان جسم با نمونههایی مشابه میتواند آن را تشخیص دهد اما اگر کاربر جسم دیگری را در کنار آن ترسیم کند، هوش مصنوعی گوگل دچار اشتباه میشود.
اما در BPS هوش مصنوعی طوری طراحی شده تا تشخیص دهد که یک شکل توسط چه خطوط و شکلهایی ترسیم میشود. برای مثال این فناوری میداند که صندلی راحتی چطور با استفاده از مستطیل و خطوط خاص ترسیم میشود.
محققان همچنین یک گام فراتر از ترسیم شکلهای مختلف برداشته و هوش مصنوعی را در جهت تشخیص حروف، کلمات و سپس جملات آموزش دادهاند.
یادگیری و تشخیص زبان، بسیار پیچیدهتر از نقاشی بوده و ما انتظار داریم که سیستم روز به روز با مفاهیم پیچیده تر آشنایی پیدا کند.
در حال حاضر این فناوری به کمک شرکتهایی مانند Avaya و برای تصحیح نام و آدرس تنها در عرض چند دقیقه، مورد استفاده قرار میگیرد.

پیش از ظهور لینک، محاورهها با رشتههای سادهای که در یک برنامه کاربردی ساخته میشدند و حتی فاقد ویژگی IntelliSense بودند، استفاده میشدند. اما با ظهور لینک، این شکل دسترسی به دادهها کاملاً متحول شد و برنامهنویسان توانستند با حداقل کدنویسی محاورهها را از یک رشته ساده خارج کرده و به محاورههایی تبدیل کنند که مدیریت بیشتر روی آنها امکانپذیر باشد. منعطف بودن لینک باعث محبوبیت آن شد. کدنویسان بدون اینکه درگیر قواعد بسیار پیچیده دسترسی به منابع دادهای مختلف شوند، موفق شدند بهراحتی برای دسترسی به دادههایی که روی منابع مختلفی همچون بانکهای اطلاعاتی رابطهای، اسناد xml و... قرار دارند، از لینک استفاده کنند. با این مقدمه، به سراغ معرفی تعدادی از تکنیکهای پرکاربرد در لینک خواهیم رفت که برای دسترسی به دادههایی که روی منابع مختلف قرار دارند، استفاده میشود. اما ابتدا باید با ساختمان درونی محاورهها در لینک آشنا شویم.
محاوره چیست؟
پرسوجو
(Query) که به نام محاوره نیز شناخته میشود، رشتهای متنی است که
بهمنظور بازیابی دادهها از یک منبع دادهای، بهروزرسانی، اضافه کردن و
حذف دادهها، از آن استفاده میشود. لینک با هدف ارائه یک مدل ساده از
محاورهها در اختیار برنامهنویسان قرار گرفت؛ مدلی که قادر است به منابع
دادهای مختلف به شیوه کدنویسی یا ویزاردی متصل شود. برای این منظور
مجموعهای از متدهای اصلی که عملگرهای استاندارد محاوره (SQO) نام دارند،
لینک را یاری میکنند. طیف گستردهای از این متدها به شکل ترتیبی کار
میکنند؛ به این معنی که شی مورد محاوره از نوع یکی از رابطهای
<IEnumerable<T یا <IQueryable<T خواهد بود. شایان ذکر است
IQueryable که برای محاورههای LINQ TO SQL استفاده میشود، در نهایت به
IEnumerable تبدیل میشود. در نتیجه یک محاوره لینک همواره با اشیا سروکار
دارد.

نکته بارز و شاخص این مدل به ویژگی یکدست بودن آن بازمیگردد؛ به طوری که برنامهنویسان در اکثر مواقع از الگوی ثابتی بهمنظور بازیابی دادهها از منابع دادهای استفاده میکنند. محاورههای ساختهشده توسط لینک، عبارات باقاعدهای هستند که همراه با فیلترهای مختلفی همچون مرتبسازی، تجمع و... قابل بهرهبرداری هستند. استخراج ساختمند دادهها در عمل به طراحان و بهویژه طراحان وب کمک فراوانی میکند. روشهای SQO روشهای توسعهیافتهای هستند که از کلاسهای Enumerable و Queryable تعریف میشوند. بعضی منابع این روشها را عملگرهای پرسوجو نامگذاری کردهاند. همگی این روشها در فضایی به نام System.Linq قرار دارند. بهطور کلی محاورهها در لینک، در پنج گروهی که در جدول شماره یک مشاهده میکنید، قرار میگیرند.

جدول شماره 1: پنج گروهی که نقش تدارکبینندهها را برای لینک بازی میکنند.
در کنار این پنج گروه اصلی، کتابخانههای جانبی دیگری نیز وجود دارند که برای مقاصد خاص استفاده میشوند.
LINQ
to Active Directory از جمله این موارد است. در میان گروههای جدول شماره
یک، دو گروه LINQ to Objects و LINQ to SQL پرکاربردترین گروههایی هستند
که برنامهنویسان استفاده میکنند. در بسیاری از موارد، برنامهنویسان
ترجیح میدهند به جای استفاده از محاورههای SQL، از محاورههایی که LINQ
to SQL در اختیار آنها قرار میدهد، استفاده کنند. به دلیل اینکه در عمل،
مکانیزم سادهتری را برای دسترسی به دادهها در اختیار آنها قرار میدهد.
در کنار این تدارکبینندهها، عملگرهای محاورهای دیگری نیز وجود دارد که
در یک عبارت محاوره از آنها استفاده میشود. پرکاربردترین این عملگرها در
جدول شماره دو آمده است.

جدول شماره 2: پرکاربردترین عملگرهایی که در محاورههای لینک استفاده میشوند.
ساختار و نحوه اجرای محاورهها در لینک
اجرای
محاورهها در لینک مکانیزم خاص خود را دارد. اولین مرحله، اتصال به منبعی
است که دادهها درون آن قرار دارند. مرحله دوم، تعریف رشته محاورهای است.
این رشته تعیینکننده منبع دادهای و دادههایی است که از آن منبع دریافت
خواهید کرد. سومین مرحله اجرای محاوره است. اجرای یک محاوره با استفاده از
حلقه foreach انجام میشود. در این حالت دادههای دریافتشده از منبع درون
یک متغیر رشتهای قرار میگیرند. زمانیکه همه عناصر پردازش شدند، رشته
قابل استفاده خواهد بود.
فهرست شماره یک، مثال سادهای از نحوه دسترسی
به یک منبع دادهای، ساخت رشته بازیابی و دریافت دادهها از این منبع را
نشان میدهد. این محاوره زمانی قابل استفاده خواهد بود که در حلقه foreach
استفاده شود. در این حالت متغیر مربوط به محاوره اجرا میشود و به سراغ
منبع دادهای خواهد رفت که برای آن تعیین شده است و در ادامه، دادهها را
بر مبنای الگویی که در محاوره مشخص شده است، دریافت خواهد کرد.
static void Main(string[] args)
{
int[] numbers = new int[7] { 0, 1, 2, 3, 4, 5, 6 };
var myQuery =
from num in numbers
where (num % 2) == 0
select num;
foreach (int num in myQuery)
{
Console.Write(“{0,1} “, num);
}
}
فهرست شماره یک
شکل 1 ساختار کلی یک محاوره و نحوه اتصال آن به یک منبع دادهای را همراه با اجزا درون محاوره نشان میدهد. نکتهای که در خصوص لینک باید به آن توجه کنید، این است که در لینک، اجرای یک محاوره متفاوت با خود محاوره است. به عبارت دیگر، با ساخت یک رشته محاورهای، هیچ دادهای در اختیار شما قرار نخواهد گرفت تا محاوره ساختهشده را اجرا کنید.

شکل 1: نحوه اجرای یک محاوره در لینک
منبع دادهای چیست؟
در
فهرست شماره یک، منبع دادهای یک آرایه بود که بهطور صریح از رابط
<IEnumerable<T پشتیبانی میکرد. این بدان معنا است که محاورههای
لینک روی اشیایی که از رابط IEnumerable ارثبری داشته باشند، بهراحتی
پیادهسازی میشوند. حلقه foreach برای اجرای محاورهها به IEnumebrale یا
<IEnumerable<T نیاز دارد. نوعهایی که از رابط <IEnumerable<T
یا رابطهایی همچون <IQueryable<T مشتق میشوند، نوعهای قابل
پرسوجو هستند. لینک میتواند از یک نوع قابل پرسوجو به شکل یک منبع داده
مستقیم، استفاده کند. اما یک منبع داده، همیشه یک آرایه ساده نیست. اگر
منبع مورد تقاضا یک بانک اطلاعاتی از نوع SQL Server باشد، تدارکبیننده
LINQ to SQL استفاده خواهد شد. در حالی که اگر منبع داده شما بانک اطلاعاتی
دیگری باشد، باید از LINQ to Dataset استفاده کنید. اگر منبع دادهای
درخواستی شما یک فایل XML باشد، تدارکبیننده LINQ to XML برای ساخت و
اجرای محاورهها استفاده میشود.
هدف از ارائه لینک کار با دادهها به
شیوه ساده و مستقیم است. لینک یک لایه برنامهنویسی انتزاعی میان زبانهای
تحت داتنت و منابع دادهای فراهم میآورد. شاید این سؤال پیش آید که چه
لزومی دارد برای دسترسی به منابع دادهای از محاورهها استفاده کنیم؟ در
پاسخ باید گفت که هر کدام از رابطهایی که برای دسترسی به دادهها از آنها
استفاده میشود، ترکیب نحوی خاص خود یا زبانی را که از آن استفاده
میکنید، در اختیار دارند؛ در نتیجه همواره باید با قواعد و ترکیبات نحوی
هر منبع دادهای و زبان برنامهنویسی هدف آشنایی داشته باشید. در مقابل
لینک این قابلیت را در اختیار شما قرار میدهد تا از چارچوب استانداردی
برای دسترسی به دادههای قرارگرفته در منابع دادهای مختلف استفاده کنید.
محاوره شماره یک؛ دسترسی به منابع دادهای ساده همچون آرایهها
آرایهها
سادهترین منبع دادهای هستند که میتوانید دادههای مدنظر را از آنها
استخراج کنید. در حالی که عناصر درون آرایهها را میتوان با استفاده از
حلقههایی همچون foreach یا for استخراج کرد، لینک نیز میتواند همین کار
را به شکل ساختیافتهای انجام دهد. فهرست شماره دو نحوه پیادهسازی یک
محاوره لینک روی یک آرایه را نشان میدهد.
static void Main(string[] args) { String[] myArray = { “One”, “Two”, “Three”, “Four”, “Five” };
var MyQuery =
from mystring
in myArray
select mystring;
foreach(var str in MyQuery)
Console.WriteLine(str); }
فهرست شماره دو
محاوره شماره دو؛ محدود کردن دادههای دریافتی از یک منبع داده
محاوره
شماره یک، همه دادههای درون یک آرایه را بازمیگرداند؛ اما اگر در نظر
داشته باشیم تنها دادههای خاص خود را استخراج کنیم، باید از کلمه کلیدی
where استفاده کنیم. این کلمه کلیدی به شما اجازه میدهد تا شرطی را روی یک
محاوره پیادهسازی کنید. در اغلب موارد، محاورهها به فیلتر نیاز دارند؛
به دلیل اینکه در بیشتر زمانها نیازی نداریم کل مجموعه دادهها را از درون
یک منبع دادهای استخراج کنیم؛ بهویژه زمانی که منبع داده هدف ما یک بانک
اطلاعاتی مشتمل بر دهها هزار رکورد باشد. مکان قرارگیری کلمه where در یک
محاوره، بعد از کلمه from و قبل از کلمه کلیدی select است. در فهرست شماره
سه از ترکیب نحوی where بهمنظور محدودکردن خروجی دادههایی که اندازه
آنها از سه کاراکتر بیشتر است، استفاده کردهایم.
static void Main(string[] args)
{
String[] myArray = { “One”, “Two”, “Three”, “Four”, “Five” };
var MyQuery =
from mystring
in myArray
where mystring.Length > 3
select mystring;
foreach(var str in MyQuery)
Console.WriteLine(str);
}
فهرست شماره سه
محاوره شماره سه؛ مرتبسازی و گروهبندی دادههای بازیافتشده در یک محاوره
برای
چینش دادههای بازیافتی در یک محاوره از کلمه کلیدی orderby استفاده
میشود. با استفاده از این کلمه کلیدی نحوه مرتبسازی دادهها، مطابق با
نیاز کاری شما خواهند بود. در کنار عملگر orderby روشها و عملگرهای دیگری
نیز برای مرتبسازی دادهها در اختیار شما قرار دارند. فهرست شماره چهار
نحوه مرتبسازی دادهها با عملگر orderby را نشان میدهد.
class Program
{
public class myclass
{
public string Name { get; set; }
public int Age { get; set; }
}
static void Main(string[] args)
{
myclass[] mystrings = { new myclass { Name=”Barley”, Age=8 },
new myclass { Name=”Boots”, Age=4 },
new myclass { Name=”Whiskers”, Age=1 } };
IEnumerable<myclass> query = mystrings.OrderBy(Program => Program.Age);
foreach (myclass mystr in query)
{
Console.WriteLine(“{0} - {1}”, mystr.Name, mystr.Age);
}
}
}
فهرست شماره چهار
محاوره شماره چهار؛ متصل کردن نتایج بهدستآمده از محاورهها
در
برخی موارد، محاورهها تنها روی یک منبع دادهای خاص اجرا نمیشوند و ما
به دادههایی نیاز داریم که درون منابع دادهای مختلف وجود دارند. در چنین
شرایطی لازم است تا محاورهها را به شکلی به یکدیگر متصل کنیم. فهرست شماره
پنج نحوه به کارگیری این تکنیک را نشان میدهد.
static void Main(string[] args)
{
Int32[] FirstArray= {1,2,3,4,5};
Int32[] SecondArray = { 6,7,8,5,4};
var MyQuery = from QueryA in FirstArray
from QueryB in SecondArray
where QueryA == QueryB
select new { QueryA, QueryB };
foreach(var str in MyQuery)
Console.WriteLine(str);
}
فهرست شماره پنج
محاروه شماره پنج؛ نحوه پیادهسازی یک شرط روی یک محاوره
بعضی
مواقع با محاورههایی برخورد میکنید که مجبور میشوید عملیاتی را روی چند
عنصر انجام دهید تا اطلاعات مورد نیازتان را دریافت کنید. اگر این عملیات
تکراری را به دفعات با محاورهها انجام دهید، وقت زیادی از شما گرفته
میشود. لینک به شما پیشنهاد میکند از Let برای ساخت مقادیر جدیدی که در
ادامه به کار میروند، استفاده کنید. فهرست شماره پنج نحوه به کارگیری کلمه
کلیدی Let را همراه با ترکیب دو محاوره با یکدیگر نشان میدهد. (شکل 2)

شکل 2: نحوه پیادهسازی یک شرط روی محاوره
static void Main(string[] args)
{
Int32[] ArrayA = {1,2,3,4};
Int32[] ArrayB = { 1,2,3,4};
var MyQuery =
from QueryA in ArrayA
from QueryB in ArrayB
let TheSquare = QueryA * QueryB
where TheSquare > 4
select new { QueryA, QueryB, TheSquare };
foreach(var str in MyQuery)
Console.WriteLine(str); }
فهرست شماره پنج
در شماره آینده به بررسی تکنیکهای دیگر مربوط به لینک خواهیم پرداخت.







