
مطلب پیشنهادی
روباتها بهزودی همه صنایع را تصرف میکنند
| نام | وزن مخصوص بر حسب کیلو گرم در متر مکعب |
|---|---|
| منیزیم | 1800 |
| آلو مینیوم آلیاژهای ساختمانی | 2700 |
| آلومینیوم | 2800 |
| آرسنیک | 5700 |
| آنتیموان | 6700 |
| کرم | 6900 |
| منگنز | 7000 |
| آهن خام خاکستری | 7200 |
| چدن | 7200 |
| روی | 7200 |
| قلع | 7400 |
| آهن سفید | 7700 |
| فولاد نرم | 7850 |
| برنز | 8500 |
| برنج ریخته گری شده | 8800 |
| نیکل | 8900 |
| مس | 8900 |
| سرب | 11400 |
| بیسموت | 9800 |
| جیوه | 13600 |
| طلا | 19300 |
| پلاتین | 21400 |

اما در ادامه، این آسانسور از کار یکنواختی که از صبح تا شب انجام میدهد خسته میشود و بهجای آنکه تنها در مسیر عمودی به حرکت خود ادامه دهد، به چپ و راست حرکت میکند تا بهنوعی اعتراض وجودی (Existential Protest) خود را به تصویر بکشد. درست است که ما هنوز چیزی بهنام آسانسور هوشمند در اختیار نداریم، اما این حرف بهمعنای آن نیست که شرکتهای بزرگ عرصه فناوری در این زمینه بیکار بودهاند. ممکن است این شرکتها نمونههای اولیهای از چنین آسانسورهایی را طراحی کرده باشند، اما ما از وجود آنها بیخبر هستیم. اگر به پیرامون خود نگاه کنیم، شاهدیم که الگوریتمهای پیچیده قادرند در حل مسائل و حتی پیشبینی وقوع جرایم به ما کمک کنند. نزدیک به یک ماه پیش در زمان نگارش این مقاله اولین روبات وکیل جهان کار خود را بهشکل گسترده در ایالات متحده آغاز کرد. چتباتی که بهمنظور مشاوره دادن به مردم در زمینه مشکلات حقوقی طراحی شده است. اما با ورود به سال 2040 شاهد حضور الگوریتمها و روباتهایی بهمراتب پیچیدهتر و کارآمدتر خواهیم بود. روباتهایی که نهتنها در زمینه پیگیری پروندهها و بررسی جرایم کارآمد خواهند بود، بلکه خود این توانایی را خواهند داشت تا جرایمی را مرتکب شوند. در آن زمان، قوانین ما چگونه قادر خواهند بود به جرایم الگوریتمهای هوشمند رسیدگی کنند؟ راه چارهای برای این مشکل وجود دارد یا از هماکنون باید به عصری سلام گوییم که بر پایه ترس و وحشت پایهگذاری خواهد شد؟ آیا بهتر نیست برنامهریزی دقیق و جامعی را برای مشکلی که ممکن است در آینده به یک چالش اصلی تبدیل شود ارائه کنیم؟ برای دستیابی به چنین پاسخهایی باید ابتدا به فکر تعریف شخصیت هوش مصنوعی باشیم.
اگر
اخبار مرتبط با هوش مصنوعی را دنبال کرده باشید، بهخوبی اطلاع دارید که
هوش مصنوعی کمتر از 50 سال دیگر یا شاید زودتر از این بازه زمانی به مغز
متفکر بسیاری از ماشینها تبدیل خواهد شد. امروزه تعداد سلولهای عصبی یک
شبکه عمیق از تعداد سلولهای عصبی موجود در مغز موجوداتی همچون زنبور عسل
یا سوسک بیشتر است و جالبتر آنکه این روند افزایش تعداد سلولهای عصبی
نهتنها متوقف نشده است، بلکه یک ماهیت تصاعدی به خود گرفته است. امروزه
الگوریتمهای هوشمندی همانند آنچه گوگل طراحی کرده است قادرند الگوریتمهای
زیستی را در مقیاس بزرگ شبیهسازی و حتی کارکردهای مغز انسان را نیز
شبیهسازی کنند. امروزه دانشمندان روی پروژههایی در حال کار هستند تا شعور
و آگاهی انسان را به درون شبکههای عمیق عصبی وارد کنند.
به طور
مثال، در پروژهای بهنام OpenWorm دانشمندان بهدنبال آن هستند تا سیستم
اعصاب مرکزی کرم الگانس را بازطراحی کنند. این کرم از آن جهت انتخاب شده
است که ما موفق شدهایم سیستم عصبی این موجود را به طور کامل نقشهبرداری و
تحلیل کنیم. سال گذشته میلادی از 175 متخصص برتر حوزه هوش مصنوعی این سؤال
پرسیده شد که نظر آنها در ارتباط با هوش مصنوعی چیست؟ در این نظرسنجی
عدهای اعلام داشتند تا سال 2040 هوش مصنوعی همتراز با هوش انسانی خواهد
شد. 90 درصد این افراد نیز اعلام داشتند تا سال 2075 این اتفاق رخ خواهد
داد. این حرف بهمعنای آن است که تا پیش از رسیدن به این سالها هوش مصنوعی
از هوش حیوانی پیشی خواهد گرفت و به همین دلیل است که این فرضیه مطرح شده
است که همان گونه که ما برای حیوانات حقوقی قائل هستیم، برای هوش مصنوعی
نیز باید چنین حقوقی را در نظر بگیریم. به این ترتیب، باید ابزارهایی همچون
آسانسورهای هوشمند را ملزم کنیم مطابق با قوانین وضع شده تنها در حالت
عمومی حرکت کنند. (شکل 1)
 شکل 1
شکل 1

بیل تامسون نویسنده نامآشنای حوزه فناوری چند سال قبل گفت: «اگر بهدنبال آن باشیم تا هوش مصنوعی کاملاً مطیع را توسعه دهیم، بهطوری که همیشه فرمانبر باشد، در عمل هیچگاه موفق نخواهیم شد هوش مصنوعی مستقلی را طراحی کنیم.»
بسیاری از کارشناسان حوزه فناوری بر این باورند که درباره هوش مصنوعی و خطرات آن کمی اغراق شده است. به طوری که هوش مصنوعی آن گونه که در فیلمها به آن پرداخته شده است، هیچگاه قادر نخواهد بود جوامع بشری را در معرض تهدید جدی قرار دهد. اما واقعیت این است که فناوری میتواند به یک ماهیت ترسناک تبدیل شود. بهویژه زمانی که با ماهیتی روبهرو میشویم که جدید و قدرتمند بوده و با سؤالات مبهم بسیاری احاطه شده است. در حالی که فیلمهایی همچون نابودگر و غرب وحشی بیشتر بر جنبه سرگرمی هوش مصنوعی متمرکز بودند، اما دورنمایی اجمالی از آینده و خطراتی را برای ما به تصویر کشیدهاند که ممکن است در آینده ما وارث آن باشیم. تا به امروز موضوعات مختلفی در ارتباط با هوش مصنوعی مورد بررسی قرار گرفته است و کارشناسان راهکارهای بازدارندگی مختلفی را در ارتباط با این فناوری پیشنهاد دادهاند، اما در این میان نباید از نقش قانون و کارکرد آن در این زمینه غافل شویم. با وجود اطلاعرسانیهای متعدد و هشدارهای مختلف هنوز هم کارشناسان حوزه فناوری درباره چالشها و خطراتی که در آینده از جانب روباتهای پیشرفته ممکن است ما را در معرض تهدید قرار دهند، دیدگاههای متفاوتی دارند. اما واقعیت این است که فناوریهای مستقلی که قادرند بهطور مستقیم به ما آسیب وارد کنند، در عصر کنونی نیز پیرامون ما قرار دارند. از پهپادهای نظامی گرفته تا روباتهای مجری قانون همواره این احتمال وجود دارد که این ابزارهای هوشمند مرتکب اشتباهی ناخواسته شوند. به طوری که ممکن است یک فرد مظنون را به قتل برسانند و در ادامه مشخص شود شخص مذکور بیگناه بوده است. در همه این موارد روباتها ضمن آنکه به مردم آسیب وارد میکنند بهواسطه خطاهای نرمافزاری یا سهلانگاری اپراتور مسئول مرتکب عملی متضاد با هنجارهای جامعه میشوند. به عبارت دقیقتر، این روباتها یک جرم را مرتکب میشوند.

جمله معروفی در این زمینه وجود دارد که میگوید: «هر جا فرد خطاکاری وجود داشته باشد، یک فرد مدعی نیز حضور دارد.» اما اگر روزگاری روباتی اشتباهی را مرتکب شود، چه کسی را باید مقصر بدانیم؟ ممکن است در مقطع کنونی بهدلیل بیش از حد انتزاعی بودن این موضوع بتوانیم از کنار آن راحت عبور کنیم. اما نباید از این موضوع غافل شویم که چندی پیش روباتی بهخاطر خرید مواد مخدر دستگیر شد، اما بدون هیچگونه اتهامی آزاد شد. ماشین خودرانی که شرکت تسلا آن را طراحی کرده بود، باعث مرگ راننده وسیله نقلیه شد. اما سازمان ملی ایمنی ترافیک حکم خاصی در این خصوص صادر نکرد. ممکن است در مقطع فعلی مواردی که به آنها اشاره شد جزء موضوعات خاص و نادر باشند، اما زمانی که چنین فناوریهایی همهگیر شوند و چنین اتفاقاتی رخ دهد، چه کسی مسئول بروز چنین مشکلاتی خواهد بود؟
نقش قانون را در ارتباط با روباتها از زوایای مختلفی میتوان مورد بررسی قرار داد. اما قانون مرتبط با روباتها درنهایت باید به گونهای به تصویب برسد که انتظارات آحاد جامعه را برآورده سازد. در جوامع بشری زمانی که به فردی حمله میشود، شخص مذکور از فرد مهاجم شکایت میکند و انتظار دارد فرد خاطی به سزای اعمال خود برسد. امروزه رانندگان وسایل نقلیه خودشان تصمیم میگیرند چه زمانی سرعت وسیله نقلیه را افزایش دهند یا از محدوده سرعت مطمئنه عبور کنند. در چنین شرایطی اگر مرتکب تخلفی شویم، از دیدگاه قانون ما مقصر هستیم. اما زمانی که مالک یک ماشین خودران میشوید و تصمیمگیریها بر عهده ماشین قرار میگیرد، همه چیز متفاوت میشود. اگر ماشین به طور ناخواسته با سرعتی مافوق تصور به حرکت ادامه دهد و خسارتهایی را به بار آورد، چه کسی مقصر است؟ مالک ماشین؟ سازندهای که ماشین را ساخته است؟ توسعهدهندهای که الگوریتم هوشمند را نوشته است؟ و... امروزه قانون به دستیاران شخصی همچون آلکسا، سیری یا کورتانا یا چتباتهای هوشمند بهعنوان یک شخص واقعی نگاه نمیکند، زیرا این الگوریتم های هوشمند در حال حاضر قادر نیستند آسیب جدی به ما وارد کنند یا جرمی مرتکب شوند. اما اگر فرزندان پیشرفتهتر این دستیاران شخصی در آینده آسیبهای واقعی به ما وارد کنند، چه اتفاقی رخ خواهد داد؟

برای آنکه بتوانیم به این پرسش پاسخ دهیم، ابتدا باید به دو سؤال پیشنیاز به این پرسش پاسخ دهیم. زمانی که روباتها عملی انجام میدهند که باعث آسیب مردم میشود یا بهنوعی ضرر و زیانی را بارِ آنها میکند، چه کسی مسئول است؟ دوم آنکه در زمینه وقوع جرم ما همواره بهدنبال انگیزه و نیت انجام عمل هستیم. اگر یک روبات یا در حالت کلیتر یک ماشین هوشمند خود بهتنهایی مرتکب جرمی شود، قانون باید چگونه به این جرم رسیدگی کند؟ اگر ماشینها به وکلایی نیاز داشته باشند، این وکلا چگونه باید نیت جرم را تشریح یا آن را رد کنند؟ آیا قوانین امروزی حاکم بر جوامع بشری میتوانند به چنین جرائمی رسیدگی کنند؟ (البته اگر فرض کنیم وکلای روباتهای خطاکار خود یک الگوریتم هوشمند نباشند!)
امروزه
ماشینهای خودران تنها در صورتی میتوانند در جادهها به تردد بپردازند که
یک عامل انسانی پشت فرمان نشسته باشد. این قانونی است که برای امنیت مردم
تصویب شده است. اما زمانی که ماشینها به طور کامل خودکار شوند، باید
قوانین جامعتری وضع شود تا نحوه تعامل انسان و ماشین را مورد بررسی قرار
دهند. مشخص است روزگاری که هوش مصنوعی بر هوش انسانی غلبه کند، از کنترل ما
خارج خواهد شد. در چنین هنگامی دیگر ما کنترلی بر ماشینهای خودران
نخواهیم داشت و همواره از بابت خساراتهایی که ممکن است به بار آورند در
هراس خواهیم بود. در آن زمان خواهیم گفت چگونه میتوانیم ماشینهای خودران
را مجازات کنیم؟ ممکن است در فیلمها و داستانهای کمیک با دورنمایی از
خطرات هوش مصنوعی آشنا شویم، اما تدوین قانونی در ارتباط با تخطی هوش
مصنوعی از دستورالعملها موضوعی نیست که با نگاه به چند فیلم بتوان آن را
نگارش و تصویب کرد. آیا روباتها روزی این توانایی را خواهند داشت تا جرمی
را مرتکب شوند؟ پاسخ این پرسش مثبت است. اگر یک روبات انسانی را به قتل
برساند، در واقع یک جرم را از دید ما مرتکب شده است. اما از دید یک روبات
او یک عنصر مادی را حذف کرده است. در نتیجه بهلحاظ فنی باید بگوییم روبات
تنها نیمی از یک جرم را مرتکب شده است، بهواسطه آنکه اثبات اینکه انگیزه
او از انجام این عمل چه بوده است کاملاً پیچیده خواهد بود. این پیچیدگی را
هماکنون نیز میتوانیم مشاهده کنیم؛ زمانی که مهندسان هوش مصنوعی گوگل با
صراحت اعلام میدارند بهدرستی نمیدانند الگوریتم هوشمند آنها بر مبنای
چه قاعدهای یک راه حل را پیشنهاد داده است.
در نتیجه به این پرسش
اساسی میرسیم که چگونه میتوانیم از انگیزه و نیت یک روبات پیش از وقوع یک
جرم اطلاع پیدا کنیم؟ ممکن است امروزه در زمینه ساخت روباتهای انساننما
با محدودیتهایی روبهرو باشیم، اما بدون تردید امروزه الگوریتمهایی را
مشاهده میکنیم که در بعضی موارد بهشکلی تبعیضآمیز با مردم برخورد
میکنند. (شکل 2) (برای اطلاع در این خصوص به پرونده ویژه خرداد ماه
ماهنامه شبکه مدیریت الگوریتم/ شورش الگوریتمی مراجعه کنید.)

شکل 2
به طور مثال، فرض کنید روباتی همچون نابودگر فردی را به قتل برساند. در چنین موردی نباید بهدنبال اثبات جرم باشیم، بلکه باید بهدنبال نیت و انگیزه باشیم. در این حالت به پرسشی چالشیتر میرسیم که چگونه میتوانیم از روباتها همانند انسانها بازجویی کنیم؟ آیا باید به درون لایههای مختلف شبکه عصبی آنها برویم و کدهای شرکت سازنده را مورد بررسی قرار دهیم؟ اما پرسشی بدیهیتری نیز وجود دارد. اساساً مغز و ذهن روبات چگونه بهسمت ارتکاب جرمی همچون جنایت متمایل میشود؟ وکلا چگونه میتوانند ثابت کنند که یک روبات برای دفاع از خود مرتکب قتل شده است یا برعکس روبات تا چه اندازه بهعمد این کار را انجام داده است. اگر بهدنبال آن هستیم تا بر مشکلات و چالشهایی که در آینده ممکن است از جانب هوش مصنوعی ما را تهدید کند فائق آییم، چارهای نداریم جز اینکه در ابتدا برای این عاملهای هوشمند حقوق و هویت قانونی در نظر بگیریم.

در مقطع فعلی در بسیاری از کشورها دستگاه قضا با ابزارهای غیرهوشمند روبهرو است و ترجیح میدهد اوضاع بر همین منوال باشد. در حال حاضر، زمانی که فردی با سلاح گرم مرتکب جرمی میشود، قوانین فرد خاطی را مجرم میدانند نه خود اسلحه را. زمانی که سلاحی بهواسطه یک نقص فنی در دستان صاحب خود منفجر میشود، شرکت سازنده مورد بازخواست قرار میگیرد. چنین موضوعی درباره روباتها نیز صادق است. اگر به دهه 80 میلادی بازگردیم، به شرکتی برخورد میکنیم که یک روبات آموزشدهنده تنیس بهنام Athlone را ساخته بود. این روبات با عملکرد خشنی که از خود نشان داد، خبرساز شد و کار به دادگاه کشید. در آن زمان قاضی اعلام کرد این امکان وجود ندارد که بتوان از روباتها شکایت کرد، در نتیجه مدیران شرکت مقصر اصلی این پرونده هستند. مشابه چنین پروندهای در سال 2009 و این بار برای یک راننده رقم خورد. رانندهای از طریق سامانه موقعیتیاب به جادهای کوهستانی میرسد و گم میشود، به طوری که درنهایت برای بازگشت از نیروهای پلیس کمک میگیرد. زمانی که راننده بهدلیل عملکرد ضعیف فناوری موقعیتیاب شکایت میکند، دادگاه راننده را به کمتوجهی در رانندگی متهم میکند. (شکل 3)

شکل 3

واقعیت
این است که فناوریهایی که در گذشته مورد استفاده قرار میدادیم، با
فناوریهایی که در زمان حال و آینده مورد استفاده قرار میدهیم تفاوتهای
بسیاری دارند. دستگاههای هوشمندی همچون ماشینهای خودران یا روباتها دیگر
همچون گذشته ابزارهای دردست انسانها نیستند. این ابزارها قادرند بهصورت
مستقل عمل و تصمیمگیری کنند. این دستگاهها با استناد به الگوریتمهای
هوشمند دادهها را جمعآوری میکنند و بر مبنای دانشی که به دست میآورند
فعالیتی را انجام میدهند. در نتیجه در زمان بروز پیامد ناگواری نمیتوان
با صراحت سازنده را مقصر دانست.
دیوید ولادک استاد حقوق دانشگاه
واشنگتن میگوید: «با توجه به اینکه امروزه افراد و شرکتهای مختلفی در
پیشبرد هوش مصنوعی ایفاگر نقش هستند، بهسختی میتوان یک فرد یا سازمان
خاصی را مسئول بروز پیشامدی دانست. با توجه به اینکه امروزه اکثر
سامانههای هوشمصنوعی بهشکلی کاملاً بسته آماده عرضه میشوند، ما در عمل
قادر نیستیم مکانیسمی را که این سامانهها بر مبنای آن کار میکنند تحلیل
کنیم.» شان بایرن استاد حقوق دانشگاه فلوریدا در این ارتباط میگوید:
«امروزه هوش مصنوعی بهدلیل نبود قوانین صریح و روشنی در این زمینه، این
شانس را دارد تا مدیر عامل شرکتی با مسئولیت محدود شود. در این حالت هوش
مصنوعی صاحب یک شخصیت حقوقی میشود و اگر چنین باشد، به بحث مالیات گرفتن
از هوش مصنوعی میرسیم. در نتیجه باید بگوییم صحبتهای آقای بیل گیتس
درخصوص دریافت مالیات از روباتها رنگ واقعیت به خود خواهد گرفت. اما به
این نکته توجه داشته باشید که اگر به هوش مصنوعی شخصیت حقوقی بدهید، این
احتمال وجود دارد که سازندگان آن در ساخت آن جانب احتیاط را کمتر رعایت
کنند، بهدلیل اینکه بهخوبی میدانند اگر مشکلی به وجود آید، دیگر آنها
مقصر شناخته نخواهند شد. همچنین، ما نمیتوانیم هوش مصنوعی را همانند یک
انسان مجازات یا به زندان منتقل کنیم. این حرف هیچ معنای خاصی ندارد.»
دکتر
جان داناهر استاد حقوق دانشگاه NUI Galway بر این باور است که در مقطع
فعلی نباید درباره شخصیت حقوقی روباتها صحبت کنیم. در آینده بهدلیل
تبعیضات اجتماعی و شغلی که ممکن است از جانب الگوریتمهای هوشمند رخ دهد،
سلب مسئولیت از سازندگان را به همراه خواهد داشت. اما دیدگاههای متفاوتی
نیز در این زمینه وجود دارد. یووال نوآ حراری نویسنده کتاب:
Sapiens: A Brief History of Humankind and Homo Deus: A Brief History of Tomorrow
میگوید:
«حتی اگر هوش مصنوعی هیچگاه به سطحی از آگاهی و درک کامل دست پیدا نکند،
باز هم بهلحاظ یک سری موارد سیاسی، اقتصادی و بینالمللی باید برای آن
شخصیت و حقوق قائل شد. درست به همان شکل که برای شرکتها و سازمانها تعریف
مشخص و قوانین مشخصی داریم، هوش مصنوعی این پتانسیل را دارد تا بر
سازمانها و حتی کشورها تسلط پیدا کند.»
تخلفات روباتها و هوش مصنوعی تنها در ارتباط با جرایم خشن خطرناک نیستند. روباتها و الگوریتمهای هوشمند در آینده میتوانند از کارت اعتباری شما برای خرید کالای قاچاق استفاده کنند. این یک داستانبافی سادهانگارانه نیست. چندی پیش دو طراح در کشور انگلستان روباتی را طراحی کردند که بهصورت تصادفی تصمیم گرفت از وب تاریک محصولاتی را خریداری کند. به نظر شما این روبات بهدنبال خرید چه چیزی بود؟ این روبات تقریباً همه چیز را خریداری میکرد. اکنون سازندگان این روبات مقصر خریدهای او هستند یا خود تصمیم گرفته است اقلام غیرقانونی را خریداری کند؟ شاید کمی خندهدار به نظر برسد روباتی را به زندان بفرستیم و برای او حکم حبس ابد یا 30 سال زندان در نظر بگیریم، بهواسطه آنکه هیچگاه پیر نشده و دلبستگی خاصی ندارد. (شکل 4)

شکل 4
مهمتر از این مسئله این امکان وجود دارد که روباتهای زندانبان نیز تحت تأثیر روباتهای مجرم قرار بگیرند. اگر روباتی جرمی را مرتکب شود، بهمعنای آن است که از الگوریتم قویتری استفاده میکند که میتواند بر اوضاع مسلط شود. شاید بهترین راهکار تنبیه یک روبات این باشد که کدهای آن را به گونهای بازنویسی کرد که دومرتبه مرتکب جرمی نشود.

Okay, that's pretty awesome.
An AI that vanquished humanity at perhaps the most complex traditional game on Earth was inconceivably smart. But not smart enough to survive its own replacement by an even more awesome, alien intelligence.
Google's DeepMind researchers have just announced the next evolution of their seemingly indomitable artificial intelligence – AlphaGo Zero – which has dispensed with what may have been the most inefficient resource in its ongoing quest for knowledge: humans.
Zero's predecessor, dubbed simply AlphaGo, was described as "Godlike" by one of the crestfallen human champions it bested at the ancient Chinese board game, Go, but the new evolution has refined its training arsenal by eradicating human teachings from its schooling entirely.
The AlphaGo versions that kicked our butts at Go in a series of contests this year and last year first learned to play the game by analysing thousands of human amateur and professional games, but AlphaGo Zero is entirely self-taught, learning by 100 percent independent experimentation.
 DeepMind
DeepMind
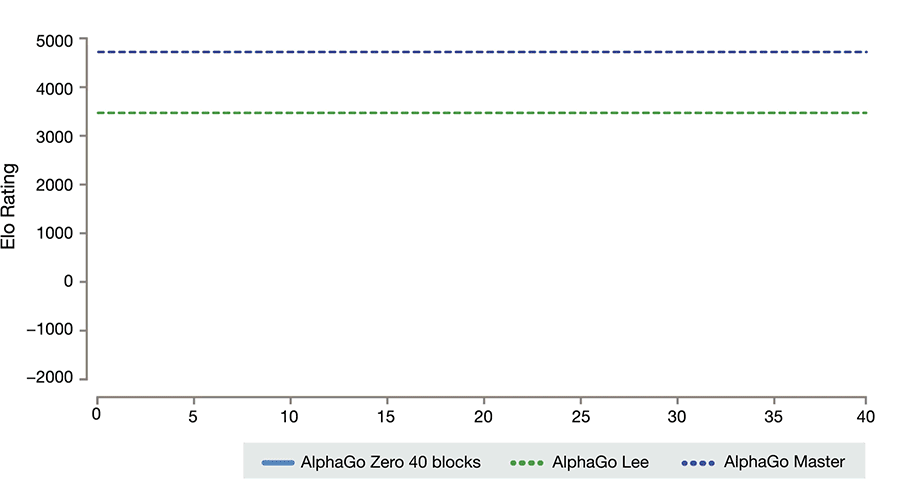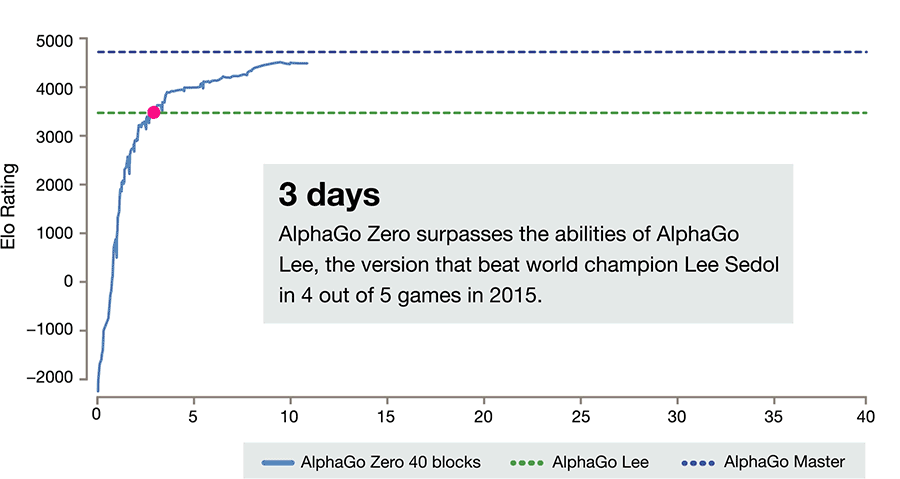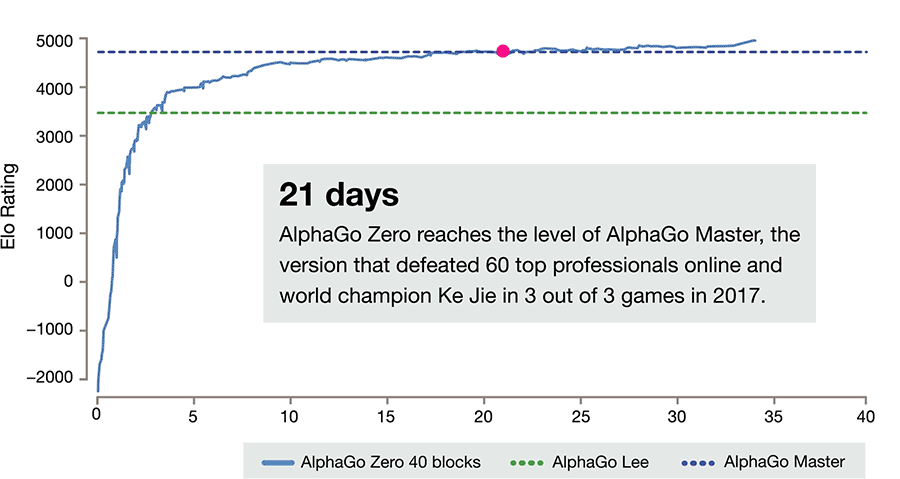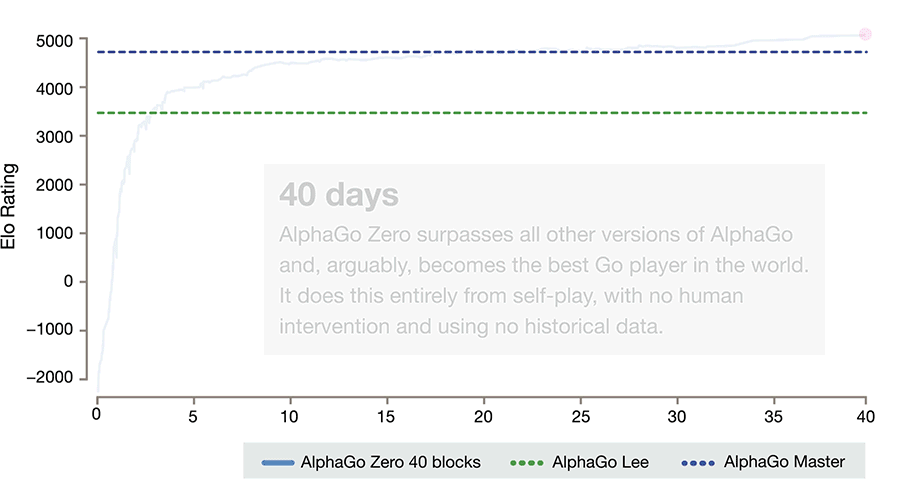
In a new study, the researchers report how that uncanny self-reliance sharpened Zero's intelligence to devastating effect: in 100 games against Zero, a previous AlphaGo incarnation – which cleaned the floor with us in 2016 – didn't pick up a single win. Not one.
Even more amazingly, that trumping came after just three days of self-play training by AlphaGo Zero, in which it distilled the equivalent of thousands of years of human knowledge of the game.
"It's like an alien civilization inventing its own mathematics," computer scientist Nick Hynes MIT told Gizmodo.
"What we're seeing here is a model free from human bias and presuppositions. It can learn whatever it determines is optimal, which may indeed be more nuanced that our own conceptions of the same."
After 21 days of self-play, Zero had progressed to the standard of its most powerful predecessor, known as AlphaGo (Master), which is the version that beat world number one Ke Jie this year, and in subsequent weeks it eclipsed that level of performance.
Aside from the self-reliance, the team behind AlphaGo Zero ascribe its Go dominance to an improved, single neural network (former versions used two in concert), and more advanced training simulations.
But just because the AI is racing ahead at such an awesome – if disquieting – pace, it doesn't necessarily mean Zero is smarter or more capable than humans in other fields away from this complex but constrained board game.
"AI fails in tasks that are surprisingly easy for humans," computational neuroscientist Eleni Vasilaki from Sheffield University in the UK told The Guardian.
"Just look at the performance of a humanoid robot in everyday tasks such as walking, running, and kicking a ball."
That may be true, but allow us our moment of silenced awe as we witness the birth of this astonishingly powerful synthetic way of thinking.
It might not do what humans can do, but it can do so many things we can't, too.
According to DeepMind, those capabilities will one day soon help Zero - or its inevitable, evolving heirs - figure out things like how biological mechanisms operate, how energy consumption can be reduced, or how new kinds of materials fit together.
Welcome to a bright new future, which clearly isn't ours alone.
The findings are reported in Nature.
- وبسایت نگین عمران: مطالبی در حوزه مهندسی و ساخت و ساز، برای مهندسین و علاقمندان به صنعت ساخت و ساز

آیا کسی هست ایموجی ها را دوست نداشته باشد؟ این شکلک های کوچک رنگارنگ همه احساسات را به خوبی انتقال می دهند خنده، گریه و ... .
اما در حالی که این شکلک های کوچک در همه تلفن های همراه به آسانی در دسترس هستند اما استفاده از آن در کامپیوتر ممکن است کمی سخت باشد.
خوشبختانه با همت مایکروسافت این صورتکهای رنگارنگ از طریق صفحه کلید لمسی که با ماوس هم می توان از آن استفاده کرد در دسترس ویندوز 10 و ویندوز 8.1 قرار گرفت. به علاوه اینکه در سالگرد به روز رسانی ویندوز 10 محموعه ای بزرگتر از ایموجی ها در دسترس قرار خواهد گرفت. لازم به ذکر است که ایموجی ها در ویندوز 7 نیز به گونه ای متفاوت از ویندوز10 و ویندوز8.1 پشتیبانی می شود.
برای دسترسی به صفحه کلید لمسی روی آیکون صفحه کلید موجود در نوار وظیفه ضربه بزنید.
کاربران ویندوز 10 اگر آیکون صفحه کلید را نمی بینید با کلیک راست روی نوار وظیفه Show touch keyboard button را انتخاب کنید.
کاربران ویندوز 8.1 با کلیک راست روی نوار وظیفه و رفتن به مسیر Toolbars و سپس Touch keyboardمی توانند آیکون صفحه کلید را ببینند.
برای استفاده از صورتک ها روی دکمه شکلک ها سمت چپ دکمه Space بزنید. مشاهده می کنید که ایموجی ها در 7 دسته قرار گرفته اند.
برای تغییر دسته ها می توانید روی دکمه های پایین صفحه کلید کلیک کنید.
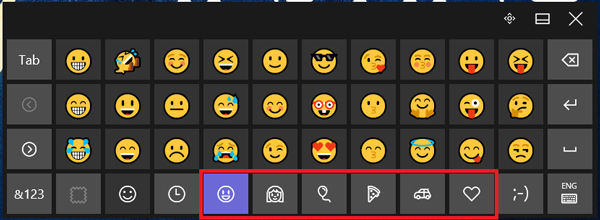
برای حرکت روی ایموجی های یک گروه روی دکمه چپ و راست سمت چپ صفحه کلید ضربه بزنید.
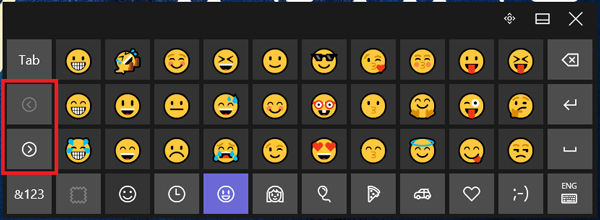
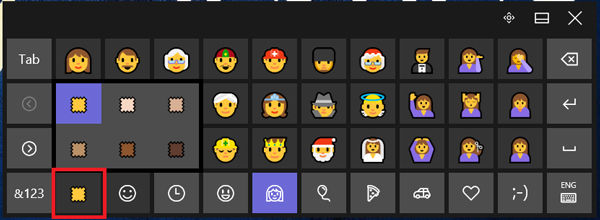
برای تغییر رنگ پوست شکلک می توانید از دکمه رنگ موجود در گوشه سمت چپ پایین صفحه استفاده کنید. با کلیک بر روی این دکمه 6 رنگ مختلف پوست به شما نشان داده می شود.
ویندوز
7 به گونه ای کاملا متفاوت ایموجی ها را پشتیبانی می کند. به این معنی که
شما می توانید با مرجعه به وب سایت ان ها را ببینید و بعد از انتخاب شکلک
با کلیدهای Ctrl + C آن را کپی و سپس با کلید های Ctrl + V در جایی که می
خواهید ایموجی را جایگذاری می کنید.
متأسفانه باید بگوییم ویندوز 7 از صفحه کلید لمسی پشتیبانی نمی کند و فقط شکلک های سیاه و سفید را پشتیبانی می کند.






