AlphaStar, playing as Zerg (in red), fighting off its human opponent.
courtesy of DeepMind
In January of this year, DeepMind announced it had hit a milestone
in its quest for artificial general intelligence. It had designed an AI
system, called AlphaStar, that beat two professional players at
StarCraft II, a popular video game about galactic warfare. This was
quite a feat. StarCaft II is highly complex, with 1026
choices for every move. It’s also a game of imperfect information—and
there are no definitive strategies for winning. The achievement marked a
new level of machine intelligence.
Now
DeepMind, an Alphabet subsidiary, is releasing an update. AlphaStar now
outranks the vast majority of active StarCraft players, demonstrating a
much more robust and repeatable ability to strategize on the fly than
before. The results, published in Nature
today, could have important implications for applications ranging from
machine translation to digital assistants or even military planning.
StarCraft II is a
real-time strategy game, most often played one on one. A player must
choose one of three human or alien races—Protoss, Terran, or Zerg—and
alternate between gathering resources, building infrastructure and
weapons, and attacking the opponent to win the game. Every race has
unique skill sets and limitations that affect the winning strategy, so
players commonly pick and master playing with one.
AlphaStar used reinforcement learning,
where an algorithm learns through trial and error, to master playing
with all the races. “This is really important because it means that the
same type of methods can in principle be applied to other domains,” said
David Silver, DeepMind’s principal research scientist, on a press call.
The AI also reached a rank above 99.8% of the active players in the
official online league.
In order to attain
such flexibility, the DeepMind team modified a commonly used technique
known as self-play, in which a reinforcement-learning algorithm plays
against itself to learn faster. DeepMind famously used this technique to
train AlphaGo Zero,
the program that taught itself without any human input to beat the best
players in the ancient game of Go. The lab also used it in the
preliminary version of AlphaStar.
Conventionally
in self-play, both versions of the algorithm are programmed to maximize
their chances of winning. But the researchers discovered that that
didn’t necessarily result in the most robust algorithms. For such an
open-ended game, it risked pigeon-holing the algorithm into specific
strategies that would only work under certain conditions.
Taking
inspiration from the way pro StarCraft II players train with one
another, the researchers instead programmed one of the algorithms to
expose the flaws of the other rather than maximize its own chance of
winning. “That’s kind of [like] asking a friend to play against you,”
said Oriol Vinyals, the lead researcher on the project, on the call.
“These friends should show you what your weaknesses are, so then
eventually you can become stronger.” The method produced much more
generalizable algorithms that could adapt to a broader range of game
scenarios.
The
researchers believe AlphaStar’s strategy development and coordination
skills could be applied to many other problems. “We chose StarCraft
[...] because we felt it mirrored a lot of challenges that actually come
up in real-world applications,” said Silver. These applications could
include digital assistants, self-driving cars, or other machines that
have to interact with humans, he said.
“The complexity [of StarCraft] is much more reminiscent of the scales that we’re seeing in the real world,” said Silver.
But
AlphaStar demonstrates AI’s significant limitations, too. For example,
it still needs orders of magnitude more training data than a human
player to attain the same level of skill. Such learning software is also
still a long way off from being translated into sophisticated robotics
or real-world applications.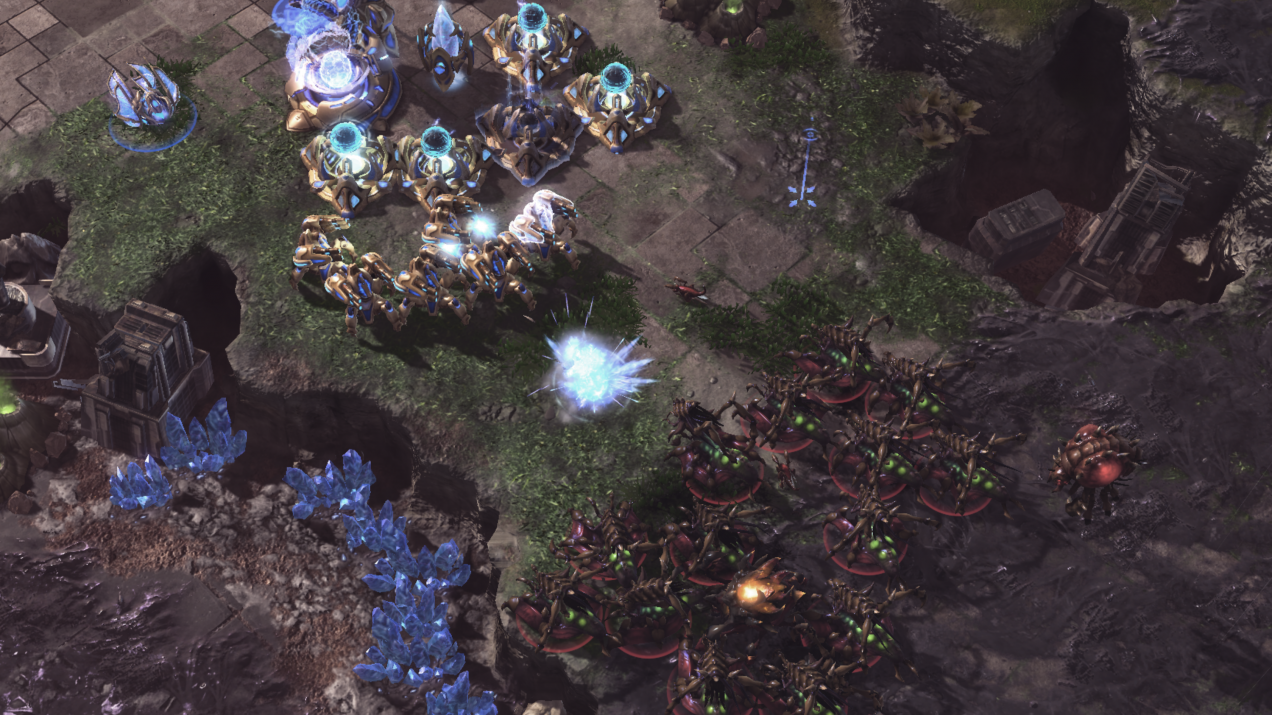






 نسخه کرک شده Codex - 1100 مگابایت
نسخه کرک شده Codex - 1100 مگابایت
 رمز:www.p30download.com
رمز:www.p30download.com منبع:پی سی دانلود
منبع:پی سی دانلود