مطلب پیشنهادی


این مطلب یکی از مجموعه مقالههای پرونده ویژه «کامپیوترهای کوانتومی» است که در شماره ۱۸۹ ماهنامه شبکه منتشر شد. برای دانلود این پرونده ویژه میتوانید اینجا کلیک کنید.
او در این ارتباط گفته است: «زمانی که یک کامپیوتر کوانتومی دیجیتالی در اختیار داشته باشید، این توانایی را دارید تا آن را برای هر مشکلی که در نظر دارید این کامپیوتر آن را حل کند، برنامهریزی کنید.» اما گوگل به دو دستاورد خیلی مهم در حوزه محاسبات کوانتومی دست پیدا کرد. شبیهسازی انرژی یک مولکول و همچنین پیادهسازی سیستم رمزنگاری جدیدی که برای مقابله با چالشهای رمزنگاری طراحی شده است در کنار طراحی یک کامپیوتر کوانتومی 48 بیتی از مهمترین دستاوردهای گوگل در حوزه محاسبات کوانتومی بهشمار میرود. ما در این مقاله بهطور مختصر و کوتاه به این دستاوردهای گوگل نگاهی خواهیم داشت.
جان مارتینی استاد فیزیک دانشگاه سانتا باربارا که رهبری آزمایشگاه محاسبات کوانتومی گوگل را بر عهده دارد، بهدنبال آن است تا مشکلات واقعی جهان امروز را حل کند. او بر این باور است که در پنج تا ده سال آینده گوگل موفق به طراحی کامپیوتر کوانتومی قدرتمندی خواهد شد که نه تنها مسائل پیچیده ریاضی را حل خواهد کرد، بلکه به مردم در اخذ یک سری تصمیمات کمک میکند. اما برای این منظور کامپیوتر کوانتومی گوگل باید از تعداد زیادی کوبیت استفاده کند. مارتینی در اولین گام سال گذشته میلادی (2016) همراه با تیم تحت سرپرستی خود موفق شد 9 بیت کوانتومی (کوبیت) را طراحی کند. اکنون او در نظر دارد این مقدار را به رقم 100 کوبیت در چند سال آینده بسط دهد. مارتینی در این ارتباط گفته است: «محاسبات کلاسیک بر مبنای ذخیرهسازی و دستکاری بیتهای ساده اطلاعات رفتار میکنند. جایی که در یک لحظه با صفرها یا یکها سر و کار دارید. در محاسبات کوانتومی از قوانینی که بر دنیای مکانیک کوانتوم حکمفرما است بهمنظور ساخت بیتهایی که میتوانند هر دو مقدار صفر یا یک را در یک لحظه در اختیار داشته باشند استفاده میکنیم. این کار به ما اجازه میدهد پردازشهای موازی را روی ماشینها ایجاد کنیم. در نتیجه بهجای آنکه یک الگوریتم حالت صفر را اجرا کرده و سپس حالت یک را اجرا کرده و در ادامه جواب را در اختیار ما قرار دهد، بهطور همزمان دو مقدار صفر و یک را اجرا میکند. این رویکرد باعث میشود تا سرعت محاسبات دو برابر شود.
واکنشهای شیمیایی که در طبیعت انجام میشوند کوانتومی هستند، بهسبب آنکه این واکنشها حالات انطباقی کوانتومی بسیار درهم تنیده دارند. در نتیجه این امکان وجود ندارد تا هر حالت ذره را بهصورت مستقل از ذرات دیگر تشریح کرد
در نتیجه با هر بار اضافه کردن کوبیتها قدرت و سرعت محاسبات افزایش پیدا میکند، بهطوری که یک روند تصاعدی پیدا خواهد کرد. این حرف بهمعنای آن است که اگر 300 کوبیت در اختیار داشته باشید، ضریب توانمندی محاسبات شما به رقم 2 به توان 300 افزایش پیدا خواهد کرد. شما در دنیای محاسبات کلاسیک نمیتوانید به چنین توانمندی در محاسبات دست پیدا کنید.»
شبیهسازی انرژی یک مولکول با استفاده از یک کامپیوتر کوانتومی
شاید بزرگترین دستاورد مهندسان گوگل در ارتباط با محاسبات کوانتومی در
شبیهسازی مولکول هیدروژن خلاصه شود. بسیاری از کارشناسان، این موفقیت گوگل
را نقطه عطفی، در محاسبات کوانتومی توصیف کردهاند. آنها برای نخستین بار
موفق شدند یک شبیهسازی کوانتومی گسترشپذیر را در ارتباط با یک مولکول
هیدروژن با موفقیت به سرانجام برسانند. این دستاورد گوگل به ما کمک خواهد
کرد تا با اتکا به محاسبات کوانتومی از اسرار دنیای شیمی که پیرامون ما
قرار دارند پرده برداریم. پژوهشگرانی که با تیم گوگل کار میکردند این
توانایی را داشتند تا به دقت انرژی مولکولهای هیدروژن H2 را شبیهسازی
کنند. اگر بتوانیم چنین رویکردی را در ارتباط با سایر مولکولها مورد
استفاده قرار دهیم، آنگاه از سلولهای خورشیدی گرفته تا پزشکی به
موفقیتهای چشمگیری دست پیدا خواهیم کرد. این چنین پیشبینیهایی برای
کامپیوترهای سنتی غیر ممکن بوده یا باید زمان بسیار زیادی را صرف چنین
فعالیتی کنند. بهطور مثال، یک ابرکامپیوتر برای آنکه بتواند انرژی مولکول
پروپان (C3H8) را شبیهسازی کند، به ده روز زمان نیاز دارد.
دستیابی به چنین شاهکاری ماحصل همکاری مشترک گروهی از مهندسان گوگل با
پژوهشگران دانشگاه هاروارد، آزمایشگاه ملی لارنس بارکلی، دانشگاه
کالیفرنیا باربارا، دانشگاه تافنز و دانشگاه کالج لندن بود. رایان بابوش
مهندس نرمافزار در واحد کوانتومی گوگل در این ارتباط گفته است: «شما این
توانایی را دارید تا انرژی مولکول هیدروژن را بهصورت کلاسیک مورد محاسبه
قرار دهید، اما این کار بهشکل ناکارآمدی انجام خواهد گرفت. در مقابل با
یک سختافزار کوانتومی این توانایی را دارید تا سیستمهای بزرگتر شیمیایی
را نیز شبیهسازی کنید.»
واکنشهای شیمیایی که در طبیعت انجام میشوند کوانتومی هستند، بهسبب آنکه
این واکنشها حالات انطباقی کوانتومی بسیار درهم تنیده دارند. در نتیجه این
امکان وجود ندارد تا هر حالت ذره را بهصورت مستقل از ذرات دیگر تشریح
کرد. همین موضوع باعث میشود کامپیوترهای کلاسیک که با مقادیر باینری سنتی
متشکل از صفرها و یکها سر و کار دارند، در شبیهسازی این حالات با مشکل
روبهرو شوند. اما در مقابل کامپیوترهای کوانتومی همچون نمونهای که گوگل
از آن استفاده کرده است با کوبیتها سر و کار دارند. کوبیتها این پتانسیل
را دارند تا در حالت (برهمنهی) قرار بگیرند. در نتیجه این توانایی را
دارند تا بهطور همزمان مقادیر صفر و یک را نشان دهند. برای انجام این
شبیهسازی مهندسان گوگل از یک فوق مدار محاسبات کوانتومی موسوم به حلکننده
کوانتومی متغیر (VQE) (سرنام Variational quantum Eigensolver) استفاده
کردند. سامانه مورد استفاده از سوی گوگل در اصل یک سیستم مدلسازی بسیار
پیشرفته است که تلاش میکند سیستم عصبی مغز انسان را بر مبنای رویکردهای
کوانتومی شبیهسازی کند. همان گونه که در شکل 1 مشاهده میکنید، منحنی
نتایج بهدست آمده از VQE با انرژی واقعی آزاد شده از مولکول هیدروژن
کاملاً منطبق بوده است.
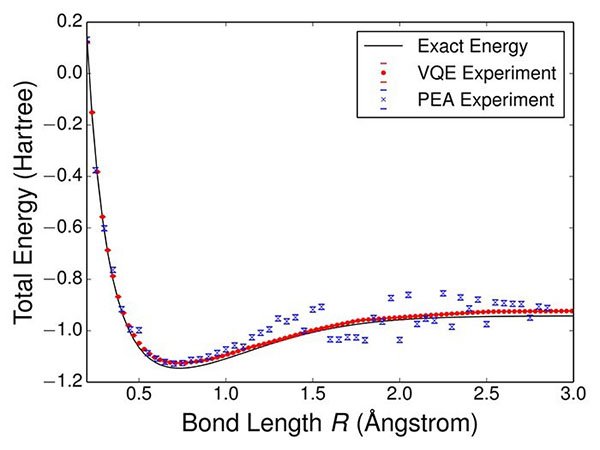
شکل 1- شبیهسازی انرژی مولکول هیدروژن بهشکل دقیقی انجام شد.
بابوش در بخشی از صحبتهای خود گفته است: «همان گونه که از شبیهسازی توصیفی و کیفی شیمیایی بهسمت شبیهسازی کیفی و قابل پیشبینی در حال حرکت هستیم، این پتانسیل را در اختیار داریم تا این حوزه از علم را بهسمت مدرنیزه شدن سوق دهیم.» ما هنوز در ابتدای مسیر قرار داریم و فقط توانستهایم نوک کوه یخ را مشاهده کنیم. گوگل در این ارتباط گفته است: «ما هنوز در ابتدای مسیر مدلسازی جهان هستی هستیم. اما این قابلیت را در اختیار داریم تا از تکنیک شبیهسازی در ارتباط با تمام سیستمهایی که بهنوعی با شیمی در ارتباط هستند استفاده کنیم. بهبود کیفیت باتریها، تجهیزات الکتریکی انعطافپذیر، بررسی اشکال جدیدی از مواد وغیره از جمله حوزههایی هستند که با شبیهسازی کوانتومی تغییرات بنیادینی را تجربه خواهند کرد.»
دفاع از سامانههای رمزنگار در برابر تهدیدات محاسبات کوانتومی
همان گونه که در مقاله چالشهای امنیتی محاسبات کوانتومی به آن اشاره
کردم، با فراگیر شدن این محاسبات در مقیاس کلان و درست زمانی که
کامپیوترهای کوانتومی از کوبیتهای بسیار زیادی استفاده کنند، دیگر
نمیتوان از الگوریتمهای رمزنگار سنتی استفاده کرد. برای حل این مشکل گوگل
بهدنبال آن است تا الگوریتم رمزنگار پساکوانتومی ویژه خود را آماده کند.
با توجه به سابقه این شرکت در ارتباط با ارائه فناوریهای زیرساختی
(پروتکل اسپیدی که از آن بهعنوان پدر پروتکل HTTP 2.0 نام برده میشود)
میتوانیم امیدوار باشیم که الگوریتم ارائه شده از سوی گوگل این پتانسیل را
خواهد داشت تا در مقیاس کلان مورد استفاده قرار گیرد.
گوگل برای آنکه اطمینان حاصل کند مرورگرش دچار چالشهای امنیتی نخواهد شد،
بهدنبال توسعه چنین الگوریتمهایی است. الگوریتمهایی که به احتمال زیاد
از کروم در برابر هکرها و حتی محاسبات کدگشای کوانتومی محافظت به عمل
خواهند آورد. مت بریثویت از مهندسان شرکت گوگل در این ارتباط گفته است:
«امروزه این فرضیه مطرح شده است که کامپیوترهای کوانتومی بدون هیچ مشکلی
قادر خواهند بود به تمام ارتباطات اینترنتی نفوذ کرده و کدگذاریهای
قدرتمند امروزی را بهسادگی در هم شکسته و به اطلاعاتی دست پیدا کنند که
برای چند دهه محرمانه بودند.
امروزه این فرضیه مطرح شده است که کامپیوترهای کوانتومی بدون هیچ مشکلی قادر خواهند بود به تمام ارتباطات اینترنتی نفوذ کرده و کدگذاریهای قدرتمند امروزی را بهسادگی در هم شکسته و به اطلاعاتی دست پیدا کنند که برای چند دهه محرمانه بودند. بر همین اساس از هماکنون باید به فکر چاره مشکلاتی باشیم که در چند سال آینده بهوجود خواهد آمد
بر همین اساس از هماکنون باید به فکر چاره مشکلاتی باشیم که در چند سال آینده بهوجود خواهد آمد.» بر همین اساس گوگل بهصورت آزمایشی بخش کوچکی از مکانیسمهای ارتباطی که میان مرورگر کروم در کامپیوترهای دسکتاپ و سرورهای گوگل برقرار میشود را با سامانه رمزنگار پساکوانتومی رمزنگاری کرده است. سامانهای که از الگوریتم رمزنگاری منحنی بیضوی استفاده میکند. گوگل بازه زمانی دو ساله را برای آزمایش این الگوریتم در نظر گرفته است. با پایان یافتن این زمان (سال 2017) و بررسی نقاط قوت و ضعف این الگوریتم، گوگل در سال آینده میلادی (2018) سامانه بهتری را جایگزین آن میکند.
گوگل چه برنامهای برای آینده دارد؟
جان مارتینی در این ارتباط گفته است: «ما در حال طراحی یک کامپیوتر
کوانتومی بر مبنای بازپخت کوانتومی شبیه به کامپیوتر کوانتومی شرکت دیویو
هستیم که در سال 2013 آن را خریداری کردیم. اما از رویکرد متفاوتی نسبت
به شرکت دیویو سیستمز استفاده میکنیم. آنها بهطور پیوسته کوبیتهای
بیشتر و بیشتری را اضافه میکنند بدون آنکه از بابت انسجام کوبیتها نگرانی
داشته باشند. ما بر این باور هستیم که اتخاذ چنین رویکردی نمیتواند
لزوماً بهمعنای قدرت بیشتر باشد. بازپخت کوانتومی به شما اجازه میدهد از
طریق پیدا کردن راه حلهای مصرف حداقل انرژی مشکلات مربوط به بهینهسازی
یک سیستم را حل کنید.
این رویکرد بهویژه در ارتباط با یادگیری ماشینی مفید است. جایی که در
تلاش هستید حداقل عملکردها را در ارتباط با پردازش حجم انبوهی از اطلاعات
در اختیار شبکه عصبی قرار دهید. یک کامپیوتر کلاسیک معمولی میتواند با یک
سامانه کوانتومی 40 تا 45 کوبیتی رقابت کند. در نتیجه در مقطع فعلی دست
یافتن به چنین کامپیوتری ایدهآل بهنظر میرسد. اما در پنج تا ده سال
آینده سعی خواهیم کرد مشکلات واقعی جهان را با سامانههای قدرتمندتری حل
کنیم. این کامپیوترها در شرایط مختلفی میتوانند به مردم کمک کنند، دستیابی
به چنین فناوری قدرتمندی واقعاً سخت است، اما در تلاش هستیم به چنین
فناوری دست پیدا کنیم.»
==============================
شاید به این مقالات هم علاقمند باشید:

رایورز - برای چندمین سال پیاپی کارشناسان و متخصصان این زبان برنامهنویسی بیشترین درخواست را برای پیدا کردن شغل جدید داشتهاند.
با اینکه پلتفرمهای گوناگونی برای تولید و توسعه نرمافزار وجود دارد، اما برخی از زبانها به دلیل جایگاه ویژهای که نزد توسعهدهندگان یافتهاند، همچنان جایگاه خود را پس از گذشت سالها نگه داشتهاند.
جاوا-اسکریپت همچنان محبوبترین زبان برنامهنویسی برای کارشناسان نرمافزار محسوب میشود. این خبر را مرکز Stack Overflow به تازگی در گزارش «چشمانداز توسعهدهندگان نرمافزاری ۲۰۱۷» خود منتشر کرده است.
به گزارش اینکوئیرر، این پلتفرم علاوه بر محبوبیت زیادی که نزد برنامهنویسان دارد، یکی از پرطرفدارترین زبانهای برنامهنویسی برای صاحبان کسب و کارها و نیز توسعهدهندگان نیز محسوب میشود.
نکته جالب توجه اینکه اکنون برای چندمین سال پیاپی است که کارشناسان و متخصصان این زبان برنامهنویسی بیشترین درخواست را برای پیدا کردن شغل جدید داشتهاند تا بتوانند جایگاهی درآمدزا برای خود دست و پا کنند.

گفتنی است برخی دیگر از زبانهای برنامهنویسی از جمله #C، Python، جاوا، PHP، ++C و C نیز در خانواده پلتفرمهای محبوب برنامهنویسی طبقهبندی میشوند، ضمن اینکه کارشناسان مسلط بر SQL نیز میانگین حقوق بالایی نسبت به دیگر متخصصان نرمافزاری دارند.
مطابق این گزارش، لیست زبانهای برنامهنویسی با بیشترین میزان استفاده و متناسب با محبوبیتشان، به قرار زیر منتشر شده است:
- جاوا-اسکریپت: ۶۵.۳ درصد
- SQL: ۵۴.۵ درصد
- C# : ۴۰.۳ درصد
- Python: ۳۰.۹ درصد
- جاوا: ۲۹.۲ درصد
- PHP: ۲۵.۶ درصد
- C++ : ۱۶.۵ درصد
- C: ۱۳.۱ درصد


رایورز - آنچه دست کم در باره سیستم عامل تازهوارد مایکروسافت میدانیم، این است که تنها قادر به اجرای اپلیکیشنهای یونیورسال است که در ویندوز استور قرار دارند.
استراتژی شرکت مایکروسافت تا امروز برای رویارویی با کرومبوکها، راهبرد سادهای مبنی بر ساخت لپتاپهای ویندوزی مقرون بهصرفه بوده است، به گونهای که بتوانند مزیت رقابتی کرومبوکها را که همان قیمت کم آنهاست، خنثی سازد و دست بالا را در این بازار داشته باشد. به نظر میرسد که مایکروسافت به فکر گسترش این راهبرد به بخش سیستم عامل خود نیز افتاده است.
به تازگی وبسایتهای Windows Blog Italia و Thurrott سیستم عامل "ویندوز کلود" را مورد بررسی قرار دادهاند. به نظر میرسد ویندوز کلود را میتوان چرخشی در ویندوز ۱۰ دانست که با هدف رقابت با کروم او.اس.اس شرکت گوگل ظهور کرده است.
عملکرد این سیستم عامل بسیار شبیه به ویندوز ۱۰ است و شاید برجستهترین ویژگی آن را بتوان این نکته دانست که در واقع تنها اپلیکیشنهای معمولی ویندوز بر روی آن قابل اجرا هستند.
به گزارش انگجت، در حال حاضر اطلاعات زیادی از این سیستم عامل تازهوارد مایکروسافت در دست نیست، اما آنچه دست کم در باره آن مطمئنیم، این است که تنها قادر به اجرای اپلیکیشنهای یونیورسال (یعنی برنامههایی که با کمک پلتفرم UWP نوشته شدهاند و قابلیت اجرا بر روی تمامی دستگاههای ویندوزی اعم از لپتاپ، تبلت و اسمارتفون را دارند) است که در ویندوز استور قرار دارند.
کارشناسان این سایتها معتقدند ویندوز کلود از لحاظ بصری هیچ گونه تفاوت عمدهای با ویندوز ۱۰ ندارد و احتمالاً برای استفاده در مدارس و مؤسساتی مناسب خواهد بود که فقدان اپلیکیشنهای بومی (Native Apps) در کروم او.اس به دلیل مسائل امنیتی را حس میکردند.
از سوی دیگر معلمان احتمالاً بیشتر مایل به استفاده از PC های ویندوزی هستند، چرا که مطمئنند سیستم آنها تحت تأثیر بدافزازها یا برنامهها و بازیهای تأیید نشده قرار نخواهد گرفت.
گفته میشود احتمال دارد شرکت مایکروسافت، فروشگاه نرمافزاری جدیدی موسوم به Centennial (که امکان بارگذاری اپلیکیشنهای ۳۲ بیتی در ویندوز استور را فراهم میکند) را نیز در نظر بگیرد. البته هنوز در مورد جزئیات و نیز سازگاری آن به دلیل وجود گزارشهایی متناقض، تردیدهایی وجود دارد.
شایان ذکر است با وجود اخباری که به تازگی در باره سیستم عامل جدید غول نرمافزاری جهان به رسانهها درز کرده، هنوز اطلاعات دقیقی در خصوص زمان عرضه ویندوز کلود وجود ندارد، اما به احتمال زیاد به زودی (در بهار ۲۰۱۷) شاهد عرضه آن خواهیم بود.

پیش از ظهور لینک، محاورهها با رشتههای سادهای که در یک برنامه کاربردی ساخته میشدند و حتی فاقد ویژگی IntelliSense بودند، استفاده میشدند. اما با ظهور لینک، این شکل دسترسی به دادهها کاملاً متحول شد و برنامهنویسان توانستند با حداقل کدنویسی محاورهها را از یک رشته ساده خارج کرده و به محاورههایی تبدیل کنند که مدیریت بیشتر روی آنها امکانپذیر باشد. منعطف بودن لینک باعث محبوبیت آن شد. کدنویسان بدون اینکه درگیر قواعد بسیار پیچیده دسترسی به منابع دادهای مختلف شوند، موفق شدند بهراحتی برای دسترسی به دادههایی که روی منابع مختلفی همچون بانکهای اطلاعاتی رابطهای، اسناد xml و... قرار دارند، از لینک استفاده کنند. با این مقدمه، به سراغ معرفی تعدادی از تکنیکهای پرکاربرد در لینک خواهیم رفت که برای دسترسی به دادههایی که روی منابع مختلف قرار دارند، استفاده میشود. اما ابتدا باید با ساختمان درونی محاورهها در لینک آشنا شویم.
محاوره چیست؟
پرسوجو
(Query) که به نام محاوره نیز شناخته میشود، رشتهای متنی است که
بهمنظور بازیابی دادهها از یک منبع دادهای، بهروزرسانی، اضافه کردن و
حذف دادهها، از آن استفاده میشود. لینک با هدف ارائه یک مدل ساده از
محاورهها در اختیار برنامهنویسان قرار گرفت؛ مدلی که قادر است به منابع
دادهای مختلف به شیوه کدنویسی یا ویزاردی متصل شود. برای این منظور
مجموعهای از متدهای اصلی که عملگرهای استاندارد محاوره (SQO) نام دارند،
لینک را یاری میکنند. طیف گستردهای از این متدها به شکل ترتیبی کار
میکنند؛ به این معنی که شی مورد محاوره از نوع یکی از رابطهای
<IEnumerable<T یا <IQueryable<T خواهد بود. شایان ذکر است
IQueryable که برای محاورههای LINQ TO SQL استفاده میشود، در نهایت به
IEnumerable تبدیل میشود. در نتیجه یک محاوره لینک همواره با اشیا سروکار
دارد.

نکته بارز و شاخص این مدل به ویژگی یکدست بودن آن بازمیگردد؛ به طوری که برنامهنویسان در اکثر مواقع از الگوی ثابتی بهمنظور بازیابی دادهها از منابع دادهای استفاده میکنند. محاورههای ساختهشده توسط لینک، عبارات باقاعدهای هستند که همراه با فیلترهای مختلفی همچون مرتبسازی، تجمع و... قابل بهرهبرداری هستند. استخراج ساختمند دادهها در عمل به طراحان و بهویژه طراحان وب کمک فراوانی میکند. روشهای SQO روشهای توسعهیافتهای هستند که از کلاسهای Enumerable و Queryable تعریف میشوند. بعضی منابع این روشها را عملگرهای پرسوجو نامگذاری کردهاند. همگی این روشها در فضایی به نام System.Linq قرار دارند. بهطور کلی محاورهها در لینک، در پنج گروهی که در جدول شماره یک مشاهده میکنید، قرار میگیرند.

جدول شماره 1: پنج گروهی که نقش تدارکبینندهها را برای لینک بازی میکنند.
در کنار این پنج گروه اصلی، کتابخانههای جانبی دیگری نیز وجود دارند که برای مقاصد خاص استفاده میشوند.
LINQ
to Active Directory از جمله این موارد است. در میان گروههای جدول شماره
یک، دو گروه LINQ to Objects و LINQ to SQL پرکاربردترین گروههایی هستند
که برنامهنویسان استفاده میکنند. در بسیاری از موارد، برنامهنویسان
ترجیح میدهند به جای استفاده از محاورههای SQL، از محاورههایی که LINQ
to SQL در اختیار آنها قرار میدهد، استفاده کنند. به دلیل اینکه در عمل،
مکانیزم سادهتری را برای دسترسی به دادهها در اختیار آنها قرار میدهد.
در کنار این تدارکبینندهها، عملگرهای محاورهای دیگری نیز وجود دارد که
در یک عبارت محاوره از آنها استفاده میشود. پرکاربردترین این عملگرها در
جدول شماره دو آمده است.

جدول شماره 2: پرکاربردترین عملگرهایی که در محاورههای لینک استفاده میشوند.
ساختار و نحوه اجرای محاورهها در لینک
اجرای
محاورهها در لینک مکانیزم خاص خود را دارد. اولین مرحله، اتصال به منبعی
است که دادهها درون آن قرار دارند. مرحله دوم، تعریف رشته محاورهای است.
این رشته تعیینکننده منبع دادهای و دادههایی است که از آن منبع دریافت
خواهید کرد. سومین مرحله اجرای محاوره است. اجرای یک محاوره با استفاده از
حلقه foreach انجام میشود. در این حالت دادههای دریافتشده از منبع درون
یک متغیر رشتهای قرار میگیرند. زمانیکه همه عناصر پردازش شدند، رشته
قابل استفاده خواهد بود.
فهرست شماره یک، مثال سادهای از نحوه دسترسی
به یک منبع دادهای، ساخت رشته بازیابی و دریافت دادهها از این منبع را
نشان میدهد. این محاوره زمانی قابل استفاده خواهد بود که در حلقه foreach
استفاده شود. در این حالت متغیر مربوط به محاوره اجرا میشود و به سراغ
منبع دادهای خواهد رفت که برای آن تعیین شده است و در ادامه، دادهها را
بر مبنای الگویی که در محاوره مشخص شده است، دریافت خواهد کرد.
static void Main(string[] args)
{
int[] numbers = new int[7] { 0, 1, 2, 3, 4, 5, 6 };
var myQuery =
from num in numbers
where (num % 2) == 0
select num;
foreach (int num in myQuery)
{
Console.Write(“{0,1} “, num);
}
}
فهرست شماره یک
شکل 1 ساختار کلی یک محاوره و نحوه اتصال آن به یک منبع دادهای را همراه با اجزا درون محاوره نشان میدهد. نکتهای که در خصوص لینک باید به آن توجه کنید، این است که در لینک، اجرای یک محاوره متفاوت با خود محاوره است. به عبارت دیگر، با ساخت یک رشته محاورهای، هیچ دادهای در اختیار شما قرار نخواهد گرفت تا محاوره ساختهشده را اجرا کنید.

شکل 1: نحوه اجرای یک محاوره در لینک
منبع دادهای چیست؟
در
فهرست شماره یک، منبع دادهای یک آرایه بود که بهطور صریح از رابط
<IEnumerable<T پشتیبانی میکرد. این بدان معنا است که محاورههای
لینک روی اشیایی که از رابط IEnumerable ارثبری داشته باشند، بهراحتی
پیادهسازی میشوند. حلقه foreach برای اجرای محاورهها به IEnumebrale یا
<IEnumerable<T نیاز دارد. نوعهایی که از رابط <IEnumerable<T
یا رابطهایی همچون <IQueryable<T مشتق میشوند، نوعهای قابل
پرسوجو هستند. لینک میتواند از یک نوع قابل پرسوجو به شکل یک منبع داده
مستقیم، استفاده کند. اما یک منبع داده، همیشه یک آرایه ساده نیست. اگر
منبع مورد تقاضا یک بانک اطلاعاتی از نوع SQL Server باشد، تدارکبیننده
LINQ to SQL استفاده خواهد شد. در حالی که اگر منبع داده شما بانک اطلاعاتی
دیگری باشد، باید از LINQ to Dataset استفاده کنید. اگر منبع دادهای
درخواستی شما یک فایل XML باشد، تدارکبیننده LINQ to XML برای ساخت و
اجرای محاورهها استفاده میشود.
هدف از ارائه لینک کار با دادهها به
شیوه ساده و مستقیم است. لینک یک لایه برنامهنویسی انتزاعی میان زبانهای
تحت داتنت و منابع دادهای فراهم میآورد. شاید این سؤال پیش آید که چه
لزومی دارد برای دسترسی به منابع دادهای از محاورهها استفاده کنیم؟ در
پاسخ باید گفت که هر کدام از رابطهایی که برای دسترسی به دادهها از آنها
استفاده میشود، ترکیب نحوی خاص خود یا زبانی را که از آن استفاده
میکنید، در اختیار دارند؛ در نتیجه همواره باید با قواعد و ترکیبات نحوی
هر منبع دادهای و زبان برنامهنویسی هدف آشنایی داشته باشید. در مقابل
لینک این قابلیت را در اختیار شما قرار میدهد تا از چارچوب استانداردی
برای دسترسی به دادههای قرارگرفته در منابع دادهای مختلف استفاده کنید.
محاوره شماره یک؛ دسترسی به منابع دادهای ساده همچون آرایهها
آرایهها
سادهترین منبع دادهای هستند که میتوانید دادههای مدنظر را از آنها
استخراج کنید. در حالی که عناصر درون آرایهها را میتوان با استفاده از
حلقههایی همچون foreach یا for استخراج کرد، لینک نیز میتواند همین کار
را به شکل ساختیافتهای انجام دهد. فهرست شماره دو نحوه پیادهسازی یک
محاوره لینک روی یک آرایه را نشان میدهد.
static void Main(string[] args) { String[] myArray = { “One”, “Two”, “Three”, “Four”, “Five” };
var MyQuery =
from mystring
in myArray
select mystring;
foreach(var str in MyQuery)
Console.WriteLine(str); }
فهرست شماره دو
محاوره شماره دو؛ محدود کردن دادههای دریافتی از یک منبع داده
محاوره
شماره یک، همه دادههای درون یک آرایه را بازمیگرداند؛ اما اگر در نظر
داشته باشیم تنها دادههای خاص خود را استخراج کنیم، باید از کلمه کلیدی
where استفاده کنیم. این کلمه کلیدی به شما اجازه میدهد تا شرطی را روی یک
محاوره پیادهسازی کنید. در اغلب موارد، محاورهها به فیلتر نیاز دارند؛
به دلیل اینکه در بیشتر زمانها نیازی نداریم کل مجموعه دادهها را از درون
یک منبع دادهای استخراج کنیم؛ بهویژه زمانی که منبع داده هدف ما یک بانک
اطلاعاتی مشتمل بر دهها هزار رکورد باشد. مکان قرارگیری کلمه where در یک
محاوره، بعد از کلمه from و قبل از کلمه کلیدی select است. در فهرست شماره
سه از ترکیب نحوی where بهمنظور محدودکردن خروجی دادههایی که اندازه
آنها از سه کاراکتر بیشتر است، استفاده کردهایم.
static void Main(string[] args)
{
String[] myArray = { “One”, “Two”, “Three”, “Four”, “Five” };
var MyQuery =
from mystring
in myArray
where mystring.Length > 3
select mystring;
foreach(var str in MyQuery)
Console.WriteLine(str);
}
فهرست شماره سه
محاوره شماره سه؛ مرتبسازی و گروهبندی دادههای بازیافتشده در یک محاوره
برای
چینش دادههای بازیافتی در یک محاوره از کلمه کلیدی orderby استفاده
میشود. با استفاده از این کلمه کلیدی نحوه مرتبسازی دادهها، مطابق با
نیاز کاری شما خواهند بود. در کنار عملگر orderby روشها و عملگرهای دیگری
نیز برای مرتبسازی دادهها در اختیار شما قرار دارند. فهرست شماره چهار
نحوه مرتبسازی دادهها با عملگر orderby را نشان میدهد.
class Program
{
public class myclass
{
public string Name { get; set; }
public int Age { get; set; }
}
static void Main(string[] args)
{
myclass[] mystrings = { new myclass { Name=”Barley”, Age=8 },
new myclass { Name=”Boots”, Age=4 },
new myclass { Name=”Whiskers”, Age=1 } };
IEnumerable<myclass> query = mystrings.OrderBy(Program => Program.Age);
foreach (myclass mystr in query)
{
Console.WriteLine(“{0} - {1}”, mystr.Name, mystr.Age);
}
}
}
فهرست شماره چهار
محاوره شماره چهار؛ متصل کردن نتایج بهدستآمده از محاورهها
در
برخی موارد، محاورهها تنها روی یک منبع دادهای خاص اجرا نمیشوند و ما
به دادههایی نیاز داریم که درون منابع دادهای مختلف وجود دارند. در چنین
شرایطی لازم است تا محاورهها را به شکلی به یکدیگر متصل کنیم. فهرست شماره
پنج نحوه به کارگیری این تکنیک را نشان میدهد.
static void Main(string[] args)
{
Int32[] FirstArray= {1,2,3,4,5};
Int32[] SecondArray = { 6,7,8,5,4};
var MyQuery = from QueryA in FirstArray
from QueryB in SecondArray
where QueryA == QueryB
select new { QueryA, QueryB };
foreach(var str in MyQuery)
Console.WriteLine(str);
}
فهرست شماره پنج
محاروه شماره پنج؛ نحوه پیادهسازی یک شرط روی یک محاوره
بعضی
مواقع با محاورههایی برخورد میکنید که مجبور میشوید عملیاتی را روی چند
عنصر انجام دهید تا اطلاعات مورد نیازتان را دریافت کنید. اگر این عملیات
تکراری را به دفعات با محاورهها انجام دهید، وقت زیادی از شما گرفته
میشود. لینک به شما پیشنهاد میکند از Let برای ساخت مقادیر جدیدی که در
ادامه به کار میروند، استفاده کنید. فهرست شماره پنج نحوه به کارگیری کلمه
کلیدی Let را همراه با ترکیب دو محاوره با یکدیگر نشان میدهد. (شکل 2)

شکل 2: نحوه پیادهسازی یک شرط روی محاوره
static void Main(string[] args)
{
Int32[] ArrayA = {1,2,3,4};
Int32[] ArrayB = { 1,2,3,4};
var MyQuery =
from QueryA in ArrayA
from QueryB in ArrayB
let TheSquare = QueryA * QueryB
where TheSquare > 4
select new { QueryA, QueryB, TheSquare };
foreach(var str in MyQuery)
Console.WriteLine(str); }
فهرست شماره پنج
در شماره آینده به بررسی تکنیکهای دیگر مربوط به لینک خواهیم پرداخت.



