واحد مشترک کمکی پژوهش و مهندسی «هوش یار-تواندار» (HT-CSURE)
Hooshyar-Tavandar Common Subsidiary Unit for Research & Engineeringواحد مشترک کمکی پژوهش و مهندسی «هوش یار-تواندار» (HT-CSURE)
Hooshyar-Tavandar Common Subsidiary Unit for Research & Engineeringپیوندهای سایتهای علمی فناوری
پیوندهای علمی مختلف
سایتها و وبلاگهای عمومی
دستههای مطالب
- اخبار و تازه ها 2451
- اخبار فضا 114
- اخبار و تازه های فناوری 2421
- مطالب و مقالات جالب و مفید مرتبط به فناوری 59
- اخبار عمومی فناوری 32
- پیشرفتهای فناوریهای نظامی 107
- اخبار و مطالب مرتبط با فناوریهای مرتبط با ایده ها و اهداف واحد 2395
- اخبار و مطالب روباتیک و هوش مصنوعی 444
- انرژیهای نو و سبز+ روشهای تازه انتقال یا تولید یا ذخیره 229
- سوخت زیستی 38
- انرژی خورشیدی 66
- همجوشی 12
- بازیافت انرژی 24
- باد و جابجایی هوا و سیال 24
- ذخیره انرژی؛ باتری و ... 24
- انرژی حرارتی 8
- سفر و سکونت در جاهای بکر و فضا 276
- روشهای تازه تولید خوراک 346
- ساخت سازه ها و سکونتگاهها 665
- ساختمان هوشمند 72
- ساختمانهای پیش ساخته و جدید 93
- ساخت مسکن و سکونتگاههای ارزان 206
- کاروان 58
- پناهگاه 62
- ساخت مهاجرنشین+مراکز جمعیتی جدید 418
- پرینترهای 3D = سه بعدی 23
- وسایل نقلیه جدید و سازگار با محیط زیست 213
- پژوهشهای پزشکی و زیستی 757
- فناوریهای پوشیدنی 134
- اخبار و مطالب عمومی فناوری اطلاعات 206
- اخبار و مطالب درپیوند با نرم افزار 79
- آینده پژوهی علمی فناوری زیستی 907
- پرواز 135
- پروژه های جاری 129
- اسباب بازی و ماکت 83
- محیط زیست کوچک و بزرگ 540
- مکانیک و مواد 58
- کسب و کار و کارآفرینی 449
- نانو فناوری 10
- ساخت خودرو 40
- ساخت کشتی و شناور 17
- ساخت هواپیما و فضاپیما 22
- مطالب و مقالات متفرقه جالب و مفید 2912
- بهداشت، سلامت، پزشکی 1077
- فرهنگی، اجتماعی، سیاسی و نظامی، مذهبی 2076
- سیاسی و نظامی 903
- فرهنگی 805
- اجتماعی 1508
- مذهبی 629
- آینده پژوهی فرهنگی، اجتماعی، سیاسی، نظامی 1071
- فلسفی 176
- آینده پژوهی مذهبی، انتظار ظهور و آخرالزمان و مرتبط 495
- حقوقی، قضایی 13
- اقتصادی 513
- مطالب درپیوند با پژوهش 16
- روان شناسی 311
- علمی - تخیلی 35
- استوره ای (اسطوره ای) - تاریخی 44
- علوم 114
- ورزش 122
- واحد 41
- معرفیهای واحد 8
- اخبار واحد 1
- پروژه ها 8
- همکاران 11
- سرمایه گذاران 2
- شرکاء 2
- سامانه 6
- آموزش عمومی واحد 10
- حقوقی قضایی واحد 8
- مجموعه پیوندها 20
- کاربردی 15
- سرگرمی 105
- آموزشی 94
- الکترونیک 13
- روباتیک 11
- هوش مصنوعی 26
- مکانیک 14
- کامپیوتر (رایانه) 23
- مهندسی عمران و ساختمان 2
- فیزیک 4
- عمومی 21
برگهها
جدیدترین یادداشتها
همه- نتایج پژوهشهایی درباره سودمندیهای شکلات تلخ و قهوه ***
- میلاد مبارک
- استراتژی پکن برای تصاحب مرزهای جدید جهان
- مرتس: جنگ در اوکراین میتواند به آلمان برسد
- چگونه میتوانیم با «ناخودآگاه» خودمان گفتگو کنیم؟
- کشف یک زبان پنهان در مغز ***
- آیا ما مریخی هستیم؟ نگاهی به فرضیه عجیب دانشمندان درباره مبدأ حیات
- حجت الاسلام و المسلمین جناب سیدمحمد خاتمی: تنها راه اصلاحات اساسی است
- میلاد مبارک
- لایحه قانونی اصلاح قسمتی از قانون تجارت
- میلاد مبارک
- تشریفات دعوت مجمع عمومی شرکت سهامی و ثبت دستور جلسه ***
- شارژ دوباره سلولهای پیر با میتوکندری تازه
- حسین ممتاز : تا کم تر از 100 سال آینده موجودی به نام انسان نخواهیم داشت! (فیلم)
- این پهپاد خورشیدی از دید تئوری تا ابد پرواز میکند(+عکس)
- شهادت تسلیت
- حسابداری صندوق و تنخواهگردان***
- روایت توماس فریدمن از جهان چندبُعدی و قرن جدید: به عصر پُلیسین (Polycene) خوش آمدید
- دان ویگینگتون اقلیمشناس برجسته آمریکایی: ناتو با جلوگیری از بارش باران، خشکسالیهای غیرطبیعی در ایران ایجاد کرده است
- برخی مواد قانونی در پیوند با هیئت مدیره در شرکتها
- گفتگوی عصر ایران با پژوهشگر حوزه سینگولاریتی آقای حسین ممتاز***
- گامهای بررسی و تصویب یا رد ترازنامه شرکت
- آشنایی با ترازنامه شرکت***
- بررسی نسخه طب سنتی و خوراک برای باز کردن رگها (عروق)
- برخی مواد قانونی
- آشنایی با مفهوم و کارکرد هیئت مدیره در شرکتها***
- بررسی مطالبی درباره هیات مدیره شرکتها در این سامانه
- نمونه هایی از آییننامه تشکیل جلسات هیات مدیره و منشور هیات مدیره
- آشنایی با نقش دبیر هیات مدیره
- ۸ اثر بلندمدت هوش مصنوعی در سال ۲۰۲۶ از نگاه «فوربس»***
- راز طول عمر در رودههای شماست
- راهنمای تنظیم صورتجلسه هیئت مدیره شرکت و برگزاری خود جلسه
- ساخت «کوره پختوپز خورشیدی» توسط دانشجوی ایرانی***
- یک عبارت سهکلمهای که باعث جلب توجه «فوری» افراد و گوش دادن به شما میشود
- آشنایی با توپی چرخ عقب پژو 405، پارس و سمند
- میلاد مبارک
- شهادت تسلیت
- شهادت تسلیت
- کشف جدید و خبر مهم در مبحث تغذیه سالمندان: راز کاهش التهاب مزمن پیری***
- پیشبینی ترسناک دانشمندان؛ پایان جهان تا ۲۵ سال دیگر و فروپاشی تمدن انسانی (+عکس)
- شهادت تسلیت
- یک روش پیشنهادی نگه داشتن خودرو (ماشین) در هنگام کار نکردن ترمز (خالی کردن یا بریدن ترمز)
- روشهای ساده پیشنهادی برای خنکسازی خود و محیط با کمک کمی آب و در نبود یا بودن برق
- تحلیلی درباره ساختار خاورمیانه پس از جنگ ایران و اسرائیل
- عید مبارک
- اقتصاد ایران در دوران حجت الاسلام و المسلمین جناب سیدمحمد خاتمی چگونه بود؟
- حجت الاسلام و المسلمین جناب سید محمد خاتمی: امیدوارم گفتگو با دنیا و نیز با مردم خودمان به عنوان یک راهبرد مهم دنبال شود
- کتاب آموزشی هوش مصنوعی؛ راهنمای یادگیری عمیق با منابع تخصصی ایرانی
- علی اکبر صالحی: با ناترازیهای زیادی مواجه هستیم؛ به ناترازی در عقل هم توجه کنیم
- از ادعای پیامبری تا کشف رازهای جهان؛ وقتی ChatGPT به توهمات کاربران دامن میزند
بایگانی
جستجو
DARPA Releases DeepDive: Open Source AI Technology

- DARPA Releases DeepDive: Open Source AI Technology - Dec 11, 2014
- For the Cat with Everything: A Robotic Mouse - Dec 02, 2014
- 10 Mind-Blowing Oculus Rift Experiments - Nov 25, 2014
- Harvard’s Microrobotics Lab Developing “RoboBees” - Nov 20, 2014
- Boston Dynamics’ Atlas Robot Masters Karate Kid Crane Stance- Nov 13, 2014
Although never been pitted against IBM's Watson, DeepDive has gone up against a more fleshy foe: the human being. Result: DeepDive beat or at least equaled humans in the time it took to complete an arduous cataloging task. These were no ordinary humans, but expert human catalogers tackling the same task as DeepDive -- to read technical journal articles and catalog them by understanding their content.
"We tested DeepDive against humans performing the same tasks and DeepDive came out ahead or at least equaled the efforts of the humans," professor Shanan Peters, who supervised the testing, told EE Times.
DeepDive is free and open-source, which was the idea of its primary programmer, Christopher Re.
"We started out as part of a machine reading project funded by DARPA in which Watson also participated," Re, a professor at Univ. of Wisconsin told EE Times. "Watson is a question-answering engine (although now it seems to be much bigger). [In contrast] DeepDive's goal is to extract lots of structured data" from unstructured data sources.
DeepDive incorporates probability-based learning algorithms as well as open-source tools such as MADlib, Impala (from Oracle), and low-level techniques, such as Hogwild, some of which have also been included in Microsoft's Adam. To build DeepDive into your application, you should be familiar with SQL and Python.
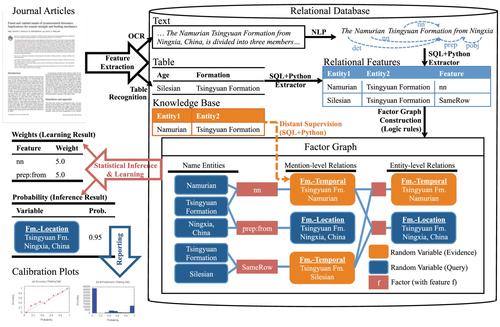
"Underneath the covers, DeepDive is based on a probability model; this is a very principled, academic approach to build these systems, but the question for use was 'could it actually scale in practice'? Our biggest innovations in Deep Dive have to do with giving it this ability to scale," Re told us.
For the future, DeepDive aims to be proven to other domains.
"We hope go have similar results in those domains soon, but it’s too early to be very specific about our plans here," Re told us. "We use a RISC processor right now, we're trying to make a compiler and we think machine learning will let us make it much easier to program in the next generation of DeepDive. We also plan to get more data types into DeepDive: images, figures, tables, charts, spreadsheets -- a sort of 'Data Omnivore' to borrow a line from Oren Etzioni."
Get all the details in the free download which are going at 10,000 per week.


























